Idomaar architecture
Idomaar architecture Idomaar framework consists of four main components:
- the orchestrator
- the evaluator
- the data container
- the computing enviroment
The computing environment consists of the code able to serve recommendation requests. The computing enviroments implements the recommendation algorithm to be experimented. Practically, the computing enviroment consists of a virtual machine that implements the code to serve recommendations. The computing environment communicates with the orchestrtor through two different publish-subscribe channels:
- A data streaming channel - consisting in an Apache Kafka connector (subscribed to the topic 'data') - It is dedicated to receive the entities and relations forming the available knowledge (e.g., used to train the recommendation algorithm). It is a unidirectional channel, where data are streamed from the orchestrator to the computing environment.
- A control channel - consisting in a ZeroMQ connector or, alternatively, a HTTP connector - dedicated to the exchange of control messages such as: the orchestrator sends a recommendation request, the computing environment notifies it is ready to serve recommendations, the computing environment replies to a recommendation request. Differently from the data streaming channel, the control channel is bidirectional.
Experimenting with Idomaar essentially means defining a computing environment that deploys a recommendation algorithm. The computing environment must be able to communicate with the orchestrator through the data streaming channel (i.e., it has to implement an Apache Kafka consumer that is subscribed to the topic 'data') and the control channel (i.e., it has to implement either a ZeroMQ or a HTTP interface).
The computing enviroment is defined in terms of Vagrant/Puppet configurations, so that it can be automatically provisioned. Idomaar uses the specified settings to start a virtual machine with the configured components (e.g., the libraries required by the software implementing the recommendation algorithms).
Examples of configurations can be found in !!TBD!!.
The orchestrator is in charge of controlling the stream of data sent to the computing environment in order to handle: batch bootstrapping, on-line data streaming, on-line recommendation request, and collection of the recommendation output.
An example of workflow is:
- The CE is booting (e.g., the user has started a CE by running
vagrant upin the/computingenvironments/01.linux/01.centos/01.mahoutdirectory). - While the CE is booting, OR periodically checks whether booting has completed by sending HTTP GET requests to the CE.
- Once the CE has finished booting, the OR starts streaming the training set (using Kafka) and notifies the CE. Upon receiving the notification, the CE starts processing the data. Once completed, the CE notifies the OR.
- The OR starts streaming recommendation requests (using Kafka) and the CE starts serving these requests (e.g., it generates recommendations for the specified user or users). When all OR requests have been served, the CE notifies the OR.
Notifications between the CE and OR are sent as either ZMQ or HTTP messages, depending on which protocol the recommender has implemented. Streaming is achieved using Kafka. However, for recommendation requests the actual communication is still done using ZMQ/HTTP (a Flume interceptor converts the requests from the Kafka stream to ZMQ/HTTP requests).
See the diagram below for an overview of how the OR interacts with other parts of the system.
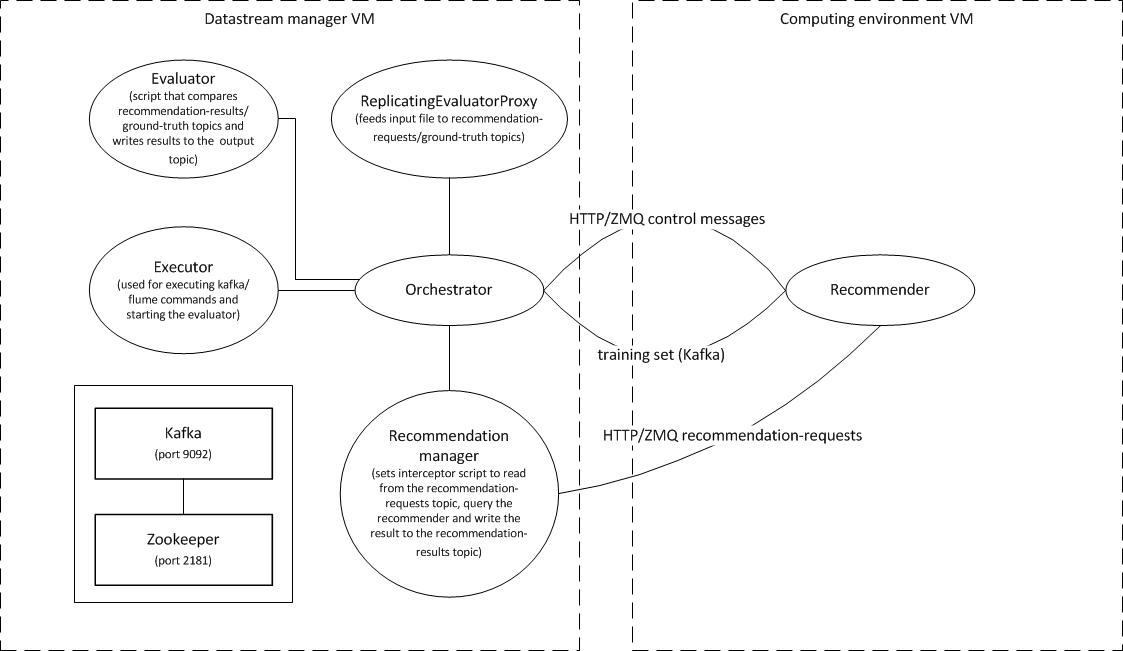
The Evaluator is the component that contains the logic required to evaluate the recommendation algorithms. In particular, the evaluator is able to (i) split the dataset according to a certain evaluation strategy and (ii) compute the quality metrics on the results returned by the recommendation algorithm.
Additional details about the evaluation logic are described in recommender evaluation.
The evaluator consists of two modules:
- the splitting module separates the data into training and test sets.
- the evaluation module computes quality and performance metrics over the experiment output.
The role of each module within the evaluation process is described in evaluation process.
The data container contains the dataset in accordance to the data model described in Data format.
In addition the data container can optionally store the split data prepared by the evaluator and the experiment output generated by the computing environment to be tested.