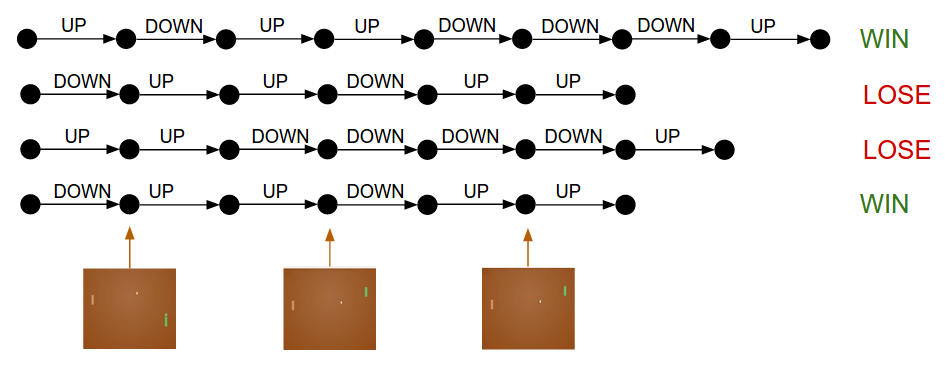
Policy gradient network is implemented using popular atari game, Pong Game. "Policy gradients method involves running a policy for a while, seeing what actions lead to high rewards, increasing their probability through backpropagating gradients".
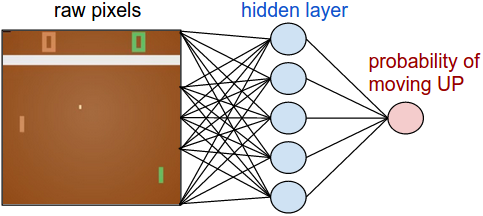
If there is a large scale problems which is aimed to solve, a type of function approximator should be used. In this problem, a neural network is used as function approximator. There are too many states and/or actions to store in memory, so look up table can not be used.
Andrej Karpathy (Deep Reinforcement Learning: Pong from Pixels): http://karpathy.github.io/2016/05/31/rl/
Policy Gradient Neural Network, based on Andrej’s solution, will do:
- take in images from the game and "preprocess" them (remove color, background, etc).
- use the TF NN to compute a probability of moving up or down.
- sample from that probability distribution and tell the agent to move up or down.
- if the round is over, find whether you won or lost.
- when the episode has finished, pass the result through the backpropagation algorithm to compute the gradient for weights.
- after each episodes have finished, sum up the gradient and move the weights in the direction of the gradient.
- repeat this process until weights are tuned to the point.
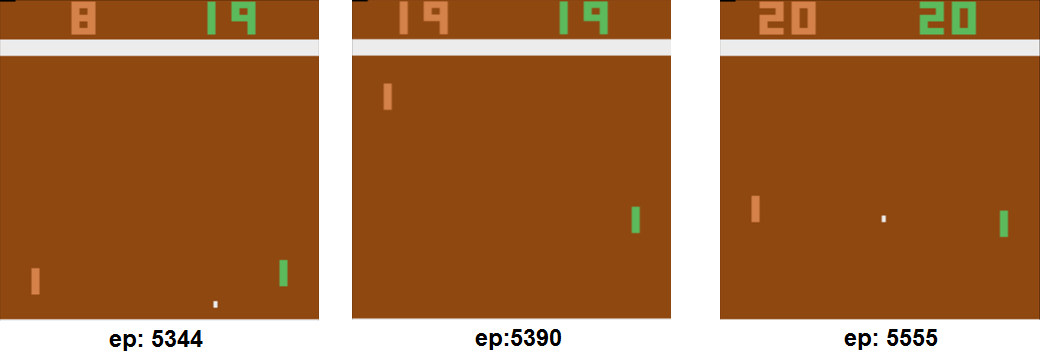
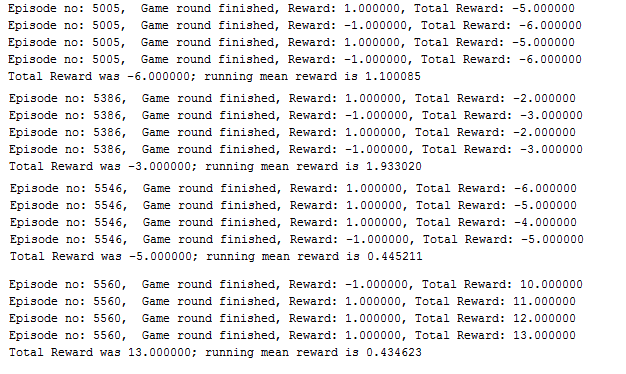
After a period time, scores are getting better.
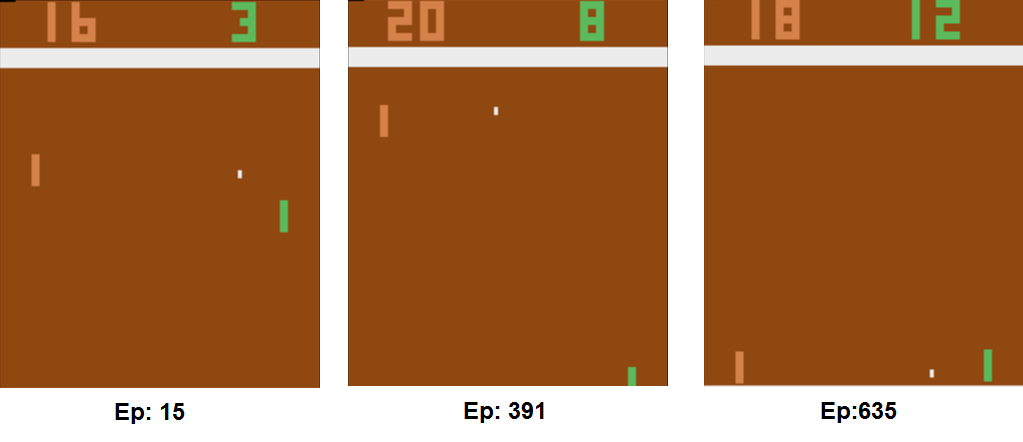
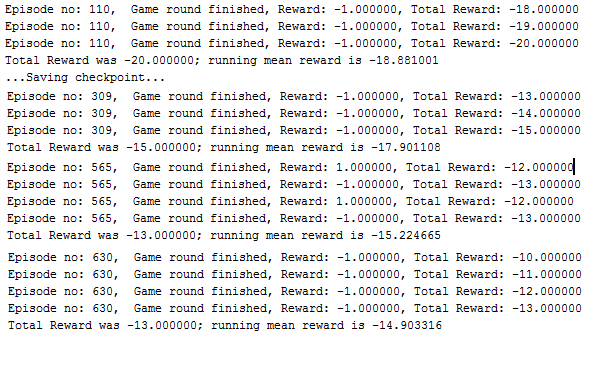
After 2 days running, system is learned and starting to beat opponent. Last saved checkpoint which is learned after 2days is committed in the checkpoint folder. When starting code in your environment, if there is a checkpoint point folder, it will be loaded..
References:
Policy Gradients Method: http://www.scholarpedia.org/article/Policy_gradient_methods
Policy Gradients from David Silver: http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching_files/pg.pdf
Pong Game Open AI Gym: https://gym.openai.com/envs/Pong-v0/
Open AI Gym: https://gym.openai.com/docs/
https://github.com/llSourcell/policy_gradients_pong
https://github.com/mrahtz/tensorflow-rl-pong
https://medium.com/@dhruvp/how-to-write-a-neural-network-to-play-pong-from-scratch-956b57d4f6e0