- Rodolfo Vasconcelos
SCS 3547 – Intelligent Agents & Reinforcement Learning
UNIVERSITY OF TORONTO - SCHOOL OF CONTINUING STUDIES
Instructor: Larry Simon
Implementation of the algorithm given on Chapter 5.4, page 101 of Sutton & Barton's book "Reinforcement Learning: An Intruduction", which is the On-policy first-visit Mont Carlo control (for epsilon-soft policies).

This algorithm to find an approximation of the optimal policy for the gridworld on page 76 and 77 of the book above.
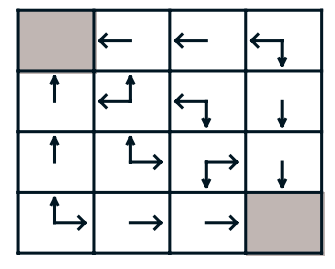
This notebook prints as output a table of the estimated q function Q(s,a) for the optimal policy and the optimal policy itself.
Note: this code was based on the Lazy Programmer's code.
The notebook can be found in the repor at monte_carlo_on_policy_first_visit_no_es_epsilon_soft_policies.ipynb or in Google Colab at https://colab.research.google.com/drive/1yJwMgv3XSZ6mLcZ1W7JAxLRZVBjHOXea?usp=sharing
This Monte Carlo algorithm produces n episodes starting from random points of the grid, and let the agent move to the four directions according to the epsilon-soft policy until a termination state is achieved.
For each episode we save the 4 values: (1) the initial state, (2) the action taken, (3) the reward received and (4) the final state.
In the end, a episode is just an array containing x arrays of these values, x being the number of steps the agent had to take until reaching a terminal state.
From these episodes, we iterate from the end of the “experience” array, and compute G as the previous state value in the same experience (weighed by gamma, the discount factor) plus the received reward in that state.
For each pair St,At that is not in the experience array:
- append G in an array of Returns(St,At)
- compute the Q(St,At) as the average of the Returns(St,At)
- get the action for the max Q(St,At)
- update the pi(a|St)
pi(a|St) contais the probalities an action can be chosen for a given state.Changing the epsilon we can change the probability the agent will be able to explore other actions insteady of choosing the best action.
Changing Epsilon you can change the probability the agent will try other actions insteady the best one.
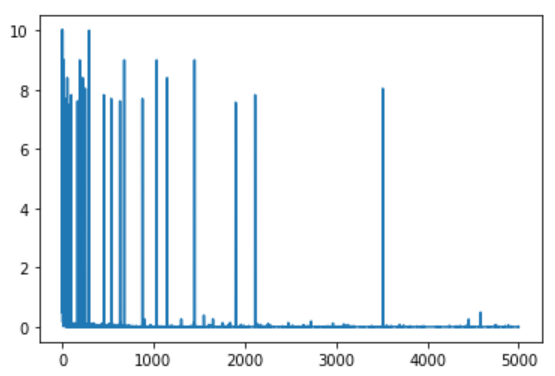
After 5000 episodes with Gamma 0.6 and Epsilon 0.3.
Q variation per episode:
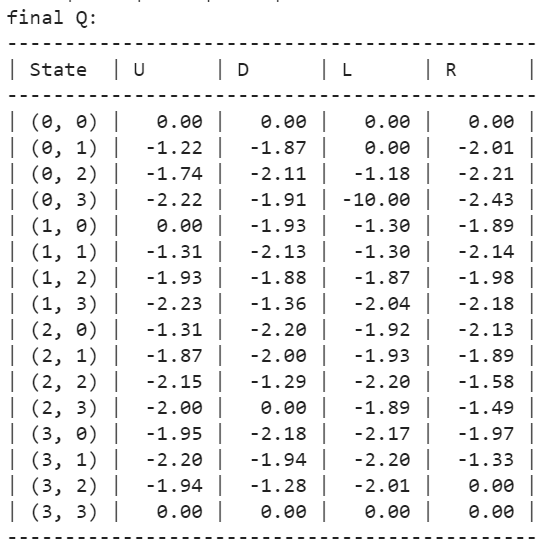
Final Q:
Final Policy:

- Gerard Martínez: Reinforcement learning (RL) 101 with Python
- Henry AI Labs: Monte Carlo Methods - Reinforcement Learning Chapter 5
- Lazy Programmer:monte_carlo_no_es
- Marcin Bogdanski: On-Policy First-Visit MC Control
- Sutton & Barton, 2018: Reinforcement Learning: An Introduction. Second edition