| 版本号 | 更新时间 | 备注 |
|---|---|---|
| V1.0 | 2019-1-20 | 首次发布 |
| V1.0.1 | 2019-4-26 | 增加了相关的知识点 |
| V2.0 | 2019-05-13 | 增加知识点,进一步完善 |
| V3.0 | 2021-04-20 | 补充整个知识体系 |
| V4.0 | 2024-1-22 | 完善整个知识体系并充实相关内容 |
Linux 运维工程师进阶升级之路由公众号【民工哥技术之路】作者【民工哥】编写、整理发布而成,我的故事: 民工哥的十年故事:杭漂十年,今撤霸都!。回头看看,写公众号也有快六年的时间了,做一件事很容易,但坚持做一件事情六年应该不是件容易的事。一路走来,收获了众多读者的肯定与支持,同时在自己的知识体系建立、建全上也取得了不小的成就。在这期间,我写的书:Linux系统运维指南 出版(2020年4月),同年10月,我拿到了2020年人民邮电出版社/异步社区《最具影响力作者》。除了感谢这个伟大的时代、家人、朋友,还要感谢无数支持我的读者们,谢谢你们。
其实,很多熟悉我的老读者都知道,我也算是 0 基础起步自学至今的,所以,对于自学,我也总结了一些方法,或者说分享一下我的经验:民工哥自学方法。对于需了解整个运维知识体系学的过程可以参考:运维工程师进阶升级之路思维导图。
现目前整个系列文章统一入口也在公众号上,后期更多增加、完善进去的内容也会统一同步发布到公众号中,欢迎大家关注(可扫文末二维码加关注哦)!!
运维工程师这个岗位不同于后端开发岗位,到底运维工程师平时做什么?老司机告诉你:正规的运维工作是什么的?。而且这个岗位对技能要求是越来越高,不仅仅要求需要知识的深度,还要求要有一定的广度,深度就是需要不断学习运维知识体系的知识,广度就是运维岗位上下游(测试与开发)岗位的一些知识体系,至少是需要做到了解基础的掌握程度。
因此,这就对运维工程师们提出了更高的要求,首先得有一颗不断学习的心,其次坚持的毅力是必须的,然后就是不断和实践、操作与总结,重复再重复, 时间久了才能形成自己的一套知识体系。
正因为这些原因,才有了上面的《运维工程师打怪升级进阶成神之路》的出现,初衷很简单,就是将我的所学与所总结的学习路线分享给大家,希望对后面的爱好者、学习 Linux 运维的朋友们有所帮助、有所借鉴。以便你们更好的学习与掌握其中的知识点,然后也能更轻松的运用到企业的实际工作中去。
V 4.0 版本是在前面几个版本的基础上更加精细化了运维岗位所需的技能知识点,更详细、更全面,几乎囊括了 Linux 系统运维岗所需的所有技能体系(如:TCP/IP 网络协议栈、Linux 常用命令、企业常用服务与应用软件、常用工具软件、Shell 脚本编程、企业监控平台、集群运维与管理、Nginx 技术栈、MySQL、PostgreSQL、Redis、MongoDB、Elasticsearch、Git、大数据 Hadoop、Kafka、RabbitMQ、Zookeeper、Docker、Kubernetes、OpenStack、DevOps、Java大后端技术等等)。
这是每一个IT从业者必备的基础中的基础,比如:TCP/IP协议、路由基础这些必备的 6 大计算机网络基础知识点!是一定要熟悉与掌握的,否则无法展开后面的系统学习的。下面一张比较全的计算网络基础的学习思维导图:
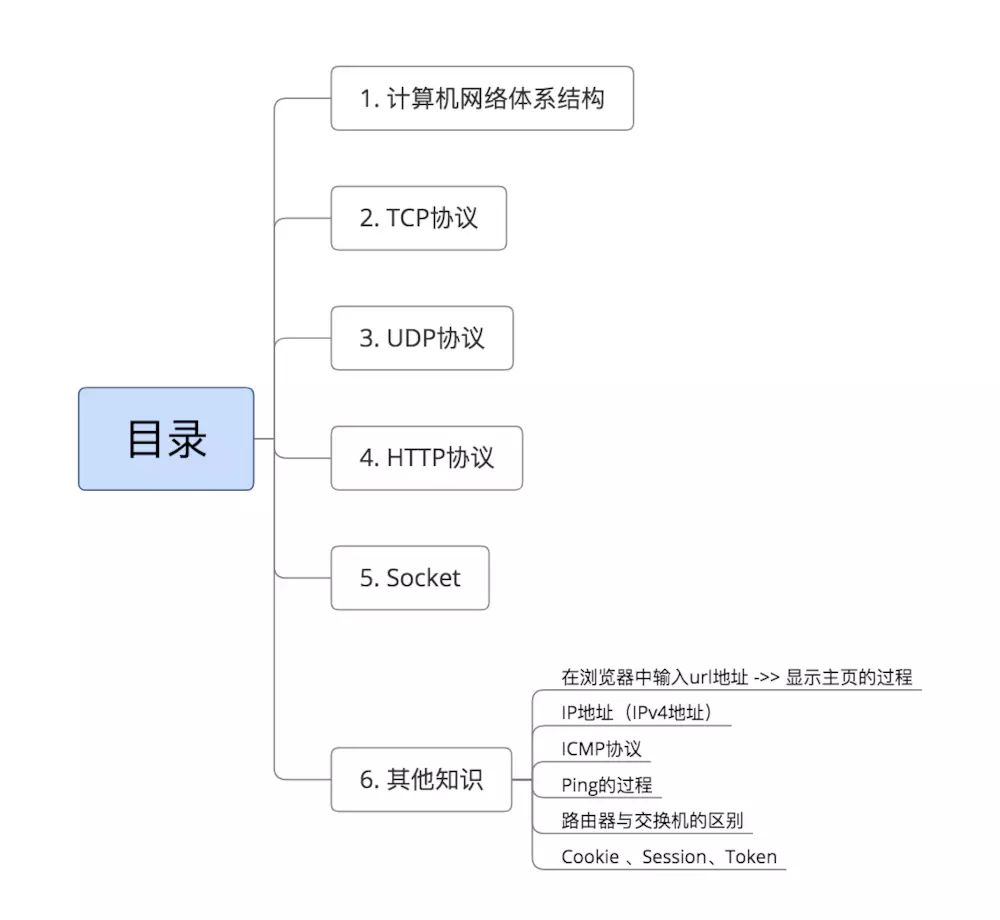
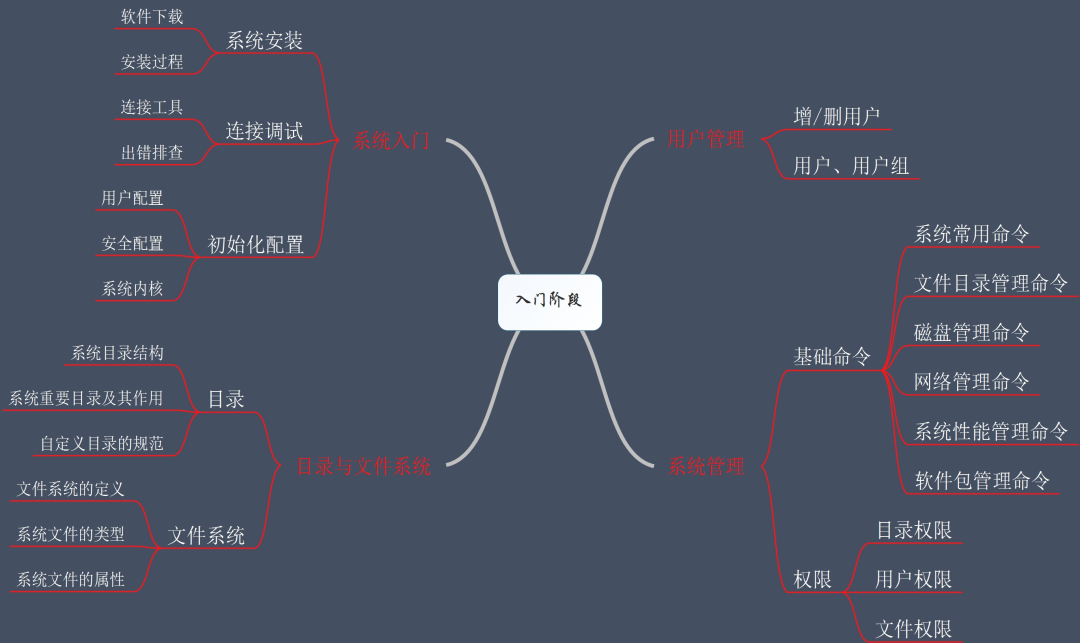
首先就是系统的安装与基础配置:Centos7安装教程,有需求的可以参考这个教程,安装其实是非常简单的。
对于系统目录、文件系统、权限等内容。前面的版本也介绍的非常清楚,这里不再一一赘述。也可以参考这里:Linux 系统基础入门知识点
这一块的知识点,在入门阶段是非常重要的一块,掌握的好坏直接影响到后面的具体操作与学习,而且,这里列举的这些常用管理命令,也是我们日常工作中要用到的(属于重点掌握内容之一)。
这部分详细介绍系统运维常用命令及其参数说明,并且配有应用案例详解,基础必备!
这部分介绍Shell脚本编程的基础入门与进阶知识,包括编写方法分享、案例分享。虽然说现在Python在运维工作中已经使用很普遍,但是很多企业实际工作中的时候还是会用到 shell 脚本,它有助于你在工作环境中自动完成很多任务。在减少重复工作量的同时,也会提高不少工作效率!因此,Shell脚本编程也是运维工程师必备的工作技能之一!
更多详细内容可以查阅专栏:Shell 脚本编程
这是一个非常基础的知识点,学习完网络、系统基础,常用命令之后,就需要完成这部分内容的学习。安装部署只是起步,真正在企业实际环境中运用自如才是王道。
玩转企业常见应用与服务系列(一):网络文件系统 NFS 原理与实践
玩转企业常见应用与服务系列(二):文件共享服务 FTP 原理与实践
玩转企业常见应用与服务系列(三):动态主机配置协议 DHCP 原理与实践
玩转企业常见应用与服务系列(四):域名系统 DNS 服务详解
玩转企业常见应用与服务系列(五):网络文件共享服务 Samba 原理与实践
玩转企业常见应用与服务系列(六):数据同步服务 lsyncd 原理与实践
玩转企业常见应用与服务系列(七):邮件服务 Postfix 原理与实践
玩转企业常见应用与服务系列(八):开源代理服务软件 Squid 详解
玩转企业常见应用与服务系列(九):开源 HTTP 加速器 Varnish 详解
玩转企业常见应用与服务系列(十):自动应答工具 expect 原理与实践
玩转企业常见应用与服务系列(十一):进程管理工具 Supervisor 详解
玩转企业常见应用与服务系列(十二):HTTP 压力测试工具 wrk 详解
玩转企业常见应用与服务系列(十三):自动化安装工具 Cobbler 详解
玩转企业常见应用与服务系列(十四):自动化运维工具 Ansible 基础入门
玩转企业常见应用与服务系列(十五):Ansible palybook 原理与实践
基础的服务安装、配置文件介绍、虚拟主机配置实践、Nginx优化配置详解、LNMP架构Nginx反向代理负载均衡配置、Nginx+Tomcat多实例及负载均衡配置、高可用、Nginx 版本的平滑升级与回滚、Nginx限流配置、Nginx日志生产实战、Nginx配置文件在线生成工具介绍等。
详细内容可以查阅专栏:Nginx 学习专栏
无论你是开发、运维,还是测试,数据库是必备的技能之一。在正式学习相关具体的数据库服务之前,我们还需要了解一下一些基础知识:可以查看:数据库基础知识专栏)。
整个知识体系包括以下几个部分。MySQL 数据库的基础知识,如:数据类型、存储引擎、性能优化(软、硬及sql语句),MySQL 数据库的高可用架构的部分,如:主从同步、读写分离的原理与实践、跨城容灾、数据的备份与恢复等,然后介绍了 MySQL 的管理命令、数据库语言的命令、库与表的管理工具、性能分析与工具的使用、MySQL 数据库服务器的硬件选型、性能监控、开发设计规范等知识。
死磕数据库系列(七):MySQL 性能优化(硬件/系统配置/表结构/SQL语句)
死磕数据库系列(十一):MySQL 日志文件解析(类型、作用)
死磕数据库系列(十二):MySQL 分库分表(何时分?怎么分?)
死磕数据库系列(十四):MySQL 锁机制详解(表级锁、页级锁、行级锁)
死磕数据库系列(十五):MySQL 存储过程、自定义函数、事务、流程控制的语法、创建和使用
死磕数据库系列(十九):MySQL 视图、触发器的原理与实战
死磕数据库系列(二十):MySQL 数据库 DDL、DML、DQL、DCL 语言理论与实践(sql 8.0 版)
死磕数据库系列(二十一):MySQL 多版本并发控制 MVCC 原理及实现
死磕数据库系列(二十二):MySQL 数据库机房架构与跨城容灾
死磕数据库系列(二十四):MySQL 级联复制与双主双从配置实战
死磕数据库系列(二十五):MySQL 高可用之组复制(MGR)详解
死磕数据库系列(二十六):MySQL 高可用之单主、双主模型组复制配置实践
死磕数据库系列(二十八):MySQL InnoDB Cluster 多节点高可用部署实战
死磕数据库系列(二十九):MySQL Router 实现数据库读写分离配置实践
死磕数据库系列(三十):MySQL 针对 Swap 分区的运维管理
死磕数据库系列(三十一):MySQL 服务器 CPU、磁盘、内存等硬件选型
死磕数据库系列(三十二):MySQL 数据库、数据表管理工具介绍
死磕数据库系列(三十三):MySQL 性能分析与相关工具的使用
死磕数据库系列(三十四):MySQL 性能测试工具 sysbench 详解
死磕数据库系列(三十六):MySQL 开发设计规范、SQL 编写规范及安全规范
PostgreSQL 是一个功能强大的开源数据库系统。经过长达15年以上的积极开发和不断改进,PostgreSQL已在可靠性、稳定性、数据一致性等获得了业内极高的声誉。目前PostgreSQL可以运行在所有主流操作系统上,包括Linux、Unix和Windows。
进阶数据库系列(二):PostgreSQL 目录结构与配置文件 postgresql.conf 详解
进阶数据库系列(四):PostgreSQL 访问控制与认证管理
进阶数据库系列(六):PostgreSQL 数据类型与运算符
进阶数据库系列(十四):PostgreSQL 事务与并发控制
进阶数据库系列(十五):PostgreSQL 主从同步原理与实践
进阶数据库系列(十六):PostgreSQL 数据库高可用方案
进阶数据库系列(十七):PostgreSQL 基于 Patroni 高可用架构部署及故障切换
进阶数据库系列(十八):PostgreSQL 基于 repmgr 高可用架构实践
进阶数据库系列(十九):PostgreSQL 基于 Pgpool 实现读写分离
进阶数据库系列(二十):PostgreSQL 数据库备份与恢复
进阶数据库系列(二十一):PostgreSQL 数据目录同步工具 pg_rewind
进阶数据库系列(二十二):PostgreSQL 数据库作业调度工具 pgAgent
进阶数据库系列(二十四):PostgreSQL 数据库日志与日常巡检
进阶数据库系列(二十五):PostgreSQL 数据库日常运维管理
进阶数据库系列(二十六):PostgreSQL 数据库监控管理
Nosql 数据库是一种非关系型数据库服务,它能解决常规数据库的并发能力,比如传统的数据库的IO与性能的瓶颈,同样它是关系型数据库的一个补充,有着比较好的高效率与高性能。专注于key-value查询的redis、memcached、ttserver。
我们这里会重点介绍:Redis、MongoDB、ElasticSearch。
Redis 是一款内存高速缓存数据库。Redis全称为:Remote Dictionary Server(远程数据服务),使用C语言编写,Redis是一个key-value存储系统(键值存储系统),支持丰富的数据类型,如:String、list、set、zset、hash。Redis是一种支持key-value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存,可持久化。
无论是运维还是开发、测试,对于 NoSQL 数据库之一的 Redis 也是必学知识体系之一。
死磕 NoSQL 数据库系列(一):Redis 基础理论与安装配置
死磕 NoSQL 数据库系列(二):Redis 9 种数据类型和应用场景
死磕 NoSQL 数据库系列(三):Redis 常用管理命令
死磕 NoSQL 数据库系列(四):Redis 发布与订阅(pub/sub)
死磕 NoSQL 数据库系列(五):Redis 事件机制详解
死磕 NoSQL 数据库系列(七):Redis 持久化(RDB和AOF)
死磕 NoSQL 数据库系列(八):Redis 主从复制及数据恢复实践
死磕 NoSQL 数据库系列(九):Redis sentinel 集群原理部署及数据恢复
死磕 NoSQL 数据库系列(十):Redis Cluster 集群分片技术
死磕 NoSQL 数据库系列(十一):Redis Cluster 交叉复制与故障切换实战
死磕 NoSQL 数据库系列(十二):使用 Redis 官方工具自动部署 Cluster 集群实践
死磕 NoSQL 数据库系列(十三):Redis Cluster 集群扩容原理与实践
死磕 NoSQL 数据库系列(十四):Redis Cluster 集群收缩原理与实践
死磕 NoSQL 数据库系列(十五):Redis 与Java\Php\Springboot 等应用的连接与使用
死磕 NoSQL 数据库系列(十六):Redis 常用运维脚本
死磕 NoSQL 数据库系列(十七):Redis 缓存问题(一致性、击穿、穿透、雪崩、污染)
死磕 NoSQL 数据库系列(十八):Redis 内存消耗及回收
死磕 NoSQL 数据库系列(十九):Redis Key 过期时间相关的命令、注意事项、回收策略
死磕 NoSQL 数据库系列(二十):Redis 性能优化与问题排查
死磕 NoSQL 数据库系列(二十一):Redis 性能测试及相关工具使用
死磕 NoSQL 数据库系列(二十二):Redis 运维监控(指标、体系建设、工具使用)
死磕 NoSQL 数据库系列(二十三):Redis 开发规范
MongoDB 是面向文档的 NoSQL 数据库,用于大量数据存储。MongoDB 是一个在 2000 年代中期问世的数据库。属于 NoSQL 数据库的类别。
硬卷 NoSQL 数据库系列(一):MongoDB 知识体系与基础概念
硬卷 NoSQL 数据库系列(二):MongoDB 安装与 CURD 基本操作
硬卷 NoSQL 数据库系列(三):MongoDB 索引与聚合
硬卷 NoSQL 数据库系列(四):MongoDB 基本使用(工具、API、Spring 集成)
硬卷 NoSQL 数据库系列(五):MongoDB 常用管理命令与授权认证
硬卷 NoSQL 数据库系列(六):MongoDB 存储引擎 WiredTiger 技术详解
硬卷 NoSQL 数据库系列(七):MongoDB 复制集技术原理详解
硬卷 NoSQL 数据库系列(八):MongoDB 集群部署与配置实践
硬卷 NoSQL 数据库系列(九):MongoDB 分片(sharding)技术
硬卷 NoSQL 数据库系列(十):MongoDB 数据库备份与恢复
硬卷 NoSQL 数据库系列(十一):MongoDB 状态检测与性能追踪
硬卷 NoSQL 数据库系列(十二):MongoDB 客户端管理工具
硬卷 NoSQL 数据库系列(十三):MongoDB 日志分析工具
硬卷 NoSQL 数据库系列(十四):MongoDB 查询聚合性能优化
硬卷 NoSQL 数据库系列(十五):MongoDB 数据库设计开发规范
ElasticSearch是一款非常强大的、基于Lucene的开源搜索及分析引擎;它是一个实时的分布式搜索分析引擎,它能让你以前所未有的速度和规模,去探索你的数据。它被用作全文检索、结构化搜索、分析以及这三个功能的组合。
除了搜索,结合Kibana、Logstash、Beats开源产品,Elastic Stack(简称ELK)还被广泛运用在大数据近实时分析领域,包括:日志分析、指标监控、信息安全等。它可以帮助你探索海量结构化、非结构化数据,按需创建可视化报表,对监控数据设置报警阈值,通过使用机器学习,自动识别异常状况。
ElasticSearch是基于Restful WebApi,使用Java语言开发的搜索引擎库类,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。其客户端在Java、C#、PHP、Python等许多语言中都是可用的。
所以,ElasticSearch具备两个优势:
- 天生支持分布式,可水平扩展;
- 提供了Restful接口,降低全文检索的学习曲线,因为Restful接口,所以可以被任何编程语言调用.
边学边实战系列(一):ElasticSearch 基础概念、生态和应用场景
边学边实战系列(二):ElasticSearch 技术原理图解
边学边实战系列(三):ElasticSearch 安装与基础使用
边学边实战系列(五):ElasticSearch DSL 查询原理与实践
边学边实战系列(六):ElasticSearch 聚合查询原理与实践
边学边实战系列(七):ElasticSearch 文档索引与读取流程详解
边学边实战系列(八):ElasticSearch 集群部署、分片与故障转移
边学边实战系列(九):ElasticSearch 集群规划与运维经验总结
边学边实战系列(十):ElasticSearch 分片/副本与数据操作流程
边学边实战系列(十一):ElasticSearch 数据备份与迁移
边学边实战系列(十二):ElasticSearch 常用 Curl 命令实践
边学边实战系列(十三):ElasticSearch 可视化管理工具
边学边实战系列(十四):ElasticSearch 性能优化详解
边学边实战系列(十五):ElasticSearch 性能监控
Tomcat 隶属于 Apache 基金会,是开源的轻量级 Web 应用服务器,使用非常广泛。客户端用户点击浏览器服务连接,浏览器通过客户端底层服务通过路由传送报文,目标服务器获取解析报文,Tomcat监听程序触发处理请求。
Tomcat 相关知识点在面试中出现的几率并不高,所以,很多人忽略了对 Tomcat 相关技能的掌握,其实它也是非常重要的知识点之一。详细内容可查阅专栏:Tomcat web 技术实践。
一个中小企业生产环境项目实践(将之前的知识连贯运用的实践):
- Linux 系统集群架构线上项目配置实战(一)
- Linux 系统集群架构线上项目配置实战(二)
- Linux 系统集群架构线上项目配置实战(三)
- Linux 系统集群架构线上项目配置实战(四)
- Linux 系统集群架构线上项目配置实战(五)
介绍常用中间件服务(Kafka\Rabbitmq\Zookeeper等)相关的日常运维所需知识体系。
Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目,该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
Kafka是一个分布式消息队列:生产者、消费者的功能。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。
Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
- 1、高吞吐量、低延迟:可以满足每秒百万级别消息的生产和消费。它的延迟最低只有几毫秒,topic可以分多个partition, consumer group 对partition进行consumer操作。
- 2、持久性、可靠性:有一套完善的消息存储机制,确保数据高效安全且持久化。消息被持久化到本地磁盘,并且支持数据备份防止数据丢失 。
- 3、分布式:基于分布式的扩展;Kafka的数据都会复制到几台服务器上,当某台故障失效时,生产者和消费者转而使用其它的Kafka。
- 4、可扩展性:kafka集群支持热扩展 。
- 5、容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)。
- 6、高并发:支持数千个客户端同时读写。
进击消息中间件系列(一):Kafka 入门(基本概念与架构)
进击消息中间件系列(三):Kafka 中 shell 命令使用
进击消息中间件系列(五):Kafka 生产者 Producer
进击消息中间件系列(六):Kafka 消费者Consumer
进击消息中间件系列(七):Kafka 控制器 Controller
进击消息中间件系列(十):Kafka 副本(Replication)机制
进击消息中间件系列(十三):Kafka 高可用与生产消费过程
进击消息中间件系列(十四):Kafka 流式 SQL 引擎 KSQL
进击消息中间件系列(十七):Kafka 集群管理工具 CMAK
进击消息中间件系列(十八):Kafka 可视化管理平台EFAK
RabbitMQ是由erlang语言开发,基于AMQP协议实现的消息队列,它是一种应用程序之间的通信方法,消息队列在分布式系统开发中应用非常广泛。
RabbitMQ 是一个消息中间件:它接受并转发消息。
你可以把它当做一个快递站点,当你要发送一个包裹时,你把你的包裹放到快递站,快递员最终会把你的快递送到收件人那里,按照这种逻辑 RabbitMQ 是 一个快递站,一个快递员帮你传递快件。RabbitMQ 与快递站的主要区别在于,它不处理快件而是接收, 存储和转发消息数据。
硬卷消息中间件系列(一):RabbitMQ 入门(核心概念与架构)
硬卷消息中间件系列(六):RabbitMQ 消息收发与交换机详解
硬卷消息中间件系列(七):RabbitMQ 消息确认机制详解
硬卷消息中间件系列(十):RabbitMQ 持久化、存储与内存管理
硬卷消息中间件系列(十一):RabbitMQ 流控、镜像队列、网络分区
硬卷消息中间件系列(十二):RabbitMQ 单机多节点、多机集群部署
硬卷消息中间件系列(十三):RabbitMQ 高可用集群部署
硬卷消息中间件系列(十五):RabbitMQ 之 Java 调用的三种方式
zooKeeper 是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。
官方文档上这么解释zookeeper,它是一个分布式协调框架,是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。是一个为分布式应用提供一致性服务的软件。
zooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
官网:https://zookeeper.apache.org/
在大型企业的开发中,服务的数量是十分庞大的。如果我们想要添加一个服务的话,那么就需要对文件进行重新覆盖,把整个容器重启。这样导致的结果是就是:波及影响太大,维护十分困难。
此时,便需要一个能够动态注册服务和获取服务信息的地方,来统一管理服务,这个地方便称为称为服务配置中心。而zookeeper不仅实现了对cusumer和provider的灵活管理,平滑过渡功能,而且还内置了负载均衡、主动通知等功能,使我们能够几乎实时的感应到服务的状态。能够很好的帮我们解决分布式相关的问题,至今仍是市面上主流的分布式服务注册中心技术之一。
进阶分布式系统架构系列(一):Zookeeper 基础概念、功能与应用场景
进阶分布式系统架构系列(二):Zookeeper 典型应用场景详解
进阶分布式系统架构系列(三):Zookeeper 部署(单机与集群)实践
进阶分布式系统架构系列(四):Zookeeper 常用管理命令
进阶分布式系统架构系列(五):Zookeeper 节点(znode)详解
进阶分布式系统架构系列(八):Zookeeper 集群 ZAB 协议
进阶分布式系统架构系列(十一):Zookeeper 数据与存储管理
进阶分布式系统架构系列(十二):Zookeeper 会话与事务管理
进阶分布式系统架构系列(十三):Zookeeper 分布式锁原理与实现
进阶分布式系统架构系列(十四):Zookeeper 开源客户端工具
进阶分布式系统架构系列(十五):Zookeeper 可视化工具
进阶分布式系统架构系列(十六):Zookeeper 实战(基于 kafka 实现的日志收集平台)
进阶分布式系统架构系列(十七):Zookeeper 运维实践经验总结
介绍 docker入门、安装、常用的命令、三剑客、私有仓库搭建以及容器监控等方面的总结。
详细内容可查阅专栏:Docker
介绍 Kubernetes 技术实践知识体系。从原理、部署开始,逐步深入去学各个知识点,比如:Pod 的实现原理、YAML语法、Kubectl使用指南、资源控制、数据存储、Harbor仓库、资源清单、服务发现、Ingress 服务、集群调度、集群管理工具、面试题、生产实践等。
详细内容可查阅专栏:k8s 技术实践
大数据(big data),指的是在一定时间范围内不能以常规软件工具处理(存储和计算)的大而复杂的数据集。说白了大数据就是使用单台计算机没法在规定时间内处理完,或者压根就没法处理的数据集。
大量 (Volume):大数据的“大”首先体现在数据量上。在实际应用中,大数据的数据量通常高达数十 TB,甚至数百 PB。高速 (Velocity):大数据的“高速”指高速接收乃至处理数据 — 数据通常直接流入内存而非写入磁盘。多样化 (Variety):多样化是指数据类型众多。
Hadoop 是用于处理大数据的工具之一。Hadoop 和其他软件产品通过特定的专有算法和方法来解释或解析大数据搜索的结果。
在大数据处理上,Hadoop并非是唯一的分布式处理架构,但是对于大部分的企业来说,基于Hadoop已经能够满足绝大部分的数据需求,因此才会成为现在的主流选择。
进击大数据系列(二):Hadoop 安装(HDFS+YARN+MapReduce)实战操作
进击大数据系列(四):Hadoop 架构基石分布式文件系统 HDFS
进击大数据系列(五):Hadoop 统一资源管理和调度平台 YARN
进击大数据系列(六):Hadoop 分布式计算框架 MapReduce
进击大数据系列(九)Hadoop 实时计算流计算引擎 Flink
进击大数据系列(十一)Hadoop 任务调度框架 Oozie
进击大数据系列(十二)Hadoop 数据同步工具 Sqoop
进击大数据系列(十三)Hadoop 分布式日志采集系统 Flume
进击大数据系列(十四)Hadoop 数据分析引擎 Apache Pig
大型网站都要面对庞大的用户量,高并发,海量数据等挑战。为了提升系统整体的性能,可以采用垂直扩展和水平扩展两种方式。
垂直扩展:在网站发展早期,可以从单机的角度通过增加硬件处理能力,比如 CPU 处理能力,内存容量,磁盘等方面,实现服务器处理能力的提升。但是,单机是有性能瓶颈的,一旦触及瓶颈,再想提升,付出的成本和代价会极高。这显然不能满足大型分布式系统(网站)所有应对的大流量,高并发,海量数据等挑战。
水平扩展:通过集群来分担大型网站的流量。集群中的应用服务器(节点)通常被设计成无状态,用户可以请求任何一个节点,这些节点共同分担访问压力。水平扩展有两个要点:
- 应用集群:将同一应用部署到多台机器上,组成处理集群,接收负载均衡设备分发的请求,进行处理,并返回相应数据。
- 负载均衡:将用户访问请求,通过某种算法,分发到集群中的节点。
集群是一组协同工作的服务集合,用来提供比单一服务更稳定、更高效、更具扩展性的服务平台。
在集群的内部,有两个或两个以上的服务实体在协调、配合完成一系列复杂的工作。
- 集群一般由两个或两个以上的服务器组建而成。每个服务器称为一个集群节点,集群节点之间可以相互通信。
- 集群应该具有节点间服务状态监控功能,同时还必须具有服务实体的扩展功能,可以灵活地增加和剔除某个服务实体。
- 集群应该具有故障自动切换功能:在集群中,同样的服务可以由多个服务实体提供。因而,当一个节点出现故障时,集群的另一个节点可以自动接管故障节点的资源,从而保证服务持久、不间断运行。
- 一个集群系统必须拥有共享的数据存储 :因为集群对外提供的服务是一致的,任何一个集群节点运行一个应用时,应用的数据都集中存储在节点共享空间内。而每个节点的操作系统上仅运行应用的服务,同时存储应用程序文件。
高可用(High availability,缩写为 HA),是指系统无中断地执行其功能的能力,代表系统的可用性程度。高可用的主要目的是为了保障“业务的连续性”,即在用户眼里,业务永远是正常对外提供服务的。
高可用是一种控制风险的能力,是一种面向风险设计,使系统具备控制风险,提供更高的可用性的能力。简单可以理解为通过种种措施使系统对外不间断地提供服务,保证服务的响应时间,减少因软件、硬件、人为造成的故障对服务的影响,在故障发生时,访问服务的用户并不会感觉到。核心就是自动检测,自动切换,自动恢复,模式有主从、双主、集群方式。
玩转企业集群运维管理系列(二):主流软件负载均衡器(LVS、Nginx、HAproxy)对比
玩转企业集群运维管理系列(三):Nginx 负载均衡原理与实践
玩转企业集群运维管理系列(四):Nginx 七层与四层反向代理详解
玩转企业集群运维管理系列(六):LVS 负载均衡(四种模式)集群配置实践
玩转企业集群运维管理系列(七):Haproxy 负载均衡详解
玩转企业集群运维管理系列(八):Haproxy 负载均衡集群部署实践
玩转企业集群运维管理系列(十):企业集群高可用软件 Keepalived 详解
玩转企业集群运维管理系列(十一):企业集群高可用软件 Keepalived 部署实践
玩转企业集群运维管理系列(十二):Keepalived 双主、非抢占模式及脑裂问题详解
玩转企业集群运维管理系列(十三):集群高可用软件 HeartBeat 详解
玩转企业集群运维管理系列(十四):Heartbeat 高可用集群部署
玩转企业集群运维管理系列(十六):DRBD 配置文件与运维管理
玩转企业集群运维管理系列(十七):高可用集群架构 corosync+pacemaker
玩转企业集群运维管理系列(十八):LVS+KeepAlived 高可用负载均衡集群原理与实践
玩转企业集群运维管理系列(十九):Haproxy+Keepalived+Nginx 实现 K8s 集群负载均衡
玩转企业集群运维管理系列(二十):Pacemaker+Corosync 高可用架构实战
玩转企业集群运维管理系列(二十一):高可用集群管理工具 RHCS 详解
分布式文件系统是分布式领域的一个基础应用,其中最著名的毫无疑问是 HDFS/GFS/ceph/MinIO 。如今该领域已经趋向于成熟,但了解它的设计要点和思想,对我们将来面临类似场景/问题时,具有借鉴意义。
详细内容可查阅专栏:分布式存储技术实践
作为目前世界上最先进的分布式版本控制系统(没有之一),Git 是一个开源的分布式版本控制软件,用以有效、高速的处理从很小到非常大的项目版本管理。Git 最初是由Linus Torvalds设计开发的,用于管理Linux内核开发。随着时间的推移,Git 发展到今天,已经成为了众多开发者必备的开发工具。
详细内容可查阅专栏:Git 技术
云计算平台也称为云平台,是指基于硬件资源和软件资源的服务,提供计算、网络和存储能力。云计算平台可以划分为3类:以数据存储为主的存储型云平台,以数据处理为主的计算型云平台以及计算和数据存储处理兼顾的综合云计算平台。
OpenStack 是由一系列具有 RESTful 接口的Web服务所实现的,是一系列组件服务集合。Openstack 是一个云平台管理的项目,我们可以使用Openstack来构建一个私有云架构,并提供IaaS的云服务。Openstack 包含三大项:计算、网络和存储。其主要目标是简化资源的配置和管理,把计算、网络和存储资源抽象成虚拟资源池,并根据需要对外提供服务。
玩转企业云计算平台系列(二):Openstack 基础环境部署
玩转企业云计算平台系列(三):Openstack 身份认证服务 Keystone
玩转企业云计算平台系列(四):Openstack 镜像服务 Glance
玩转企业云计算平台系列(五):Openstack 计算服务 Nova
玩转企业云计算平台系列(六):Openstack 网络服务 Neutron
玩转企业云计算平台系列(七):Openstack 控制面板服务 Horizon
玩转企业云计算平台系列(八):Openstack 块存储服务 Cinder
玩转企业云计算平台系列(九):Openstack 对象存储服务 Swift
玩转企业云计算平台系列(十):Openstack 基础组件使用介绍
玩转企业云计算平台系列(十一):Openstack 编排服务 Heat
玩转企业云计算平台系列(十二):Openstack 文件共享服务 Manila
玩转企业云计算平台系列(十三):Openstack 容器管理服务 Zun
玩转企业云计算平台系列(十四):Openstack 密钥管理服务 Barbican
玩转企业云计算平台系列(十五):Openstack 计费服务 Cloudkitty
玩转企业云计算平台系列(十六):Openstack Telemetry 系统架构
玩转企业云计算平台系列(十七):Openstack 大数据项目 Sahara
玩转企业云计算平台系列(十八):Openstack 部署常见问题及解决方案
- 模块松耦合:与其他开源软件相比,OpenStack模块分明。添加独立功能的组件非常简单。有时候,不需要通读整个OpenStack的代码,只需要了解其接口规范及API使用,就可以轻松地添加一个新的模块
- 组件配置较为灵活:OpenStack也需要不同的组件。但是OpenStack的组件安装异常灵活。可以全部都装在一台物理机上,也可以分散至多个物理机中,甚至可以把所有的结点都装在虚拟机中。
- 二次开发容易:OpenStack发布的OpenStack API是Rest-full API。其他所有组件也是采种这种统一的规范。因此,基于OpenStack做二次开发,较为简单。而其他3个开源软件则由于耦合性太强,导致添加功能较为困难。
- 兼容性:OpenStack兼容其他公有云,方便用户进行数据迁移。
- 可扩展性:模块化设计,可以通过横向扩展,增加节点、添加资源。
介绍日志平台相关的日常运维所需知识体系,日志管理也是日常工作中非常重要的一项内容。比较主流的是ELK stack和Graylog。ELK目前很多公司都在使用,是一种很不错的分布式日志解决方案。
详细内容可查阅专栏:日志平台。
监控系统是整个运维环节,乃至整个产品生命周期中最重要的一环,事前及时预警发现故障,事后提供翔实的数据用于追查定位问题。企业生产环境监控系统介绍,包括但不限于各类工具(Zabbix、Prometheus 等)安装、配置、优化与实践经验总以及排错等,详细的监控工具使用可查阅专栏:监控工具。
企业的IT架构逐步从传统的物理服务器,迁移到以虚拟机为主导的 IaaS 云,抑或当前流行的容器云PaaS 平台。无论基础架构如何调整,都离不开监控系统的支撑。
监控系统处理能提供实时监控和告警,还能辅助决策,所有决策都以数据为支撑,而非主观臆断。在大数据时代,数据变得越来越重要,监控数据不仅能提供实时状态展现,更能帮助故障回溯和预测风险等。当我们充分了解当前数据中心的真实资源使用情况时,才能绝对是否需要迁移服务、重新调度资源、清理垃圾数据及采购新的服务器。在故障发生后,通过分析历史监控数据,可以准确定位故障源,确定故障的发生时间及持续时间等,从而避免后续相关故障的发生。
- 从监控对象的角度来看,可以将监控分为网络监控、存储监控、服务器监控和应用监控等。
- 从程序设计的角度来看,可以将监控分为基础资源监控、中间件监控、应用程序监控和日志监控。
构建企业级监控平台系列(二):如何做好企业监控系统运维管理?
构建企业级监控平台系列(五):Zabbix、Prometheus 等开源监控系统对比分析
构建企业级监控平台系列(八):Zabbix API 使用介绍
构建企业级监控平台系列(九):Zabbix 自动发现与自动注册
构建企业级监控平台系列(十):Zabbix Proxy 原理与实践
构建企业级监控平台系列(十一):Zabbix 配置监控 Nginx、MySQL 等常见应用
构建企业级监控平台系列(十二):Prometheus 入门与安装
构建企业级监控平台系列(十三):Prometheus Server 配置详解
构建企业级监控平台系列(十四):Prometheus Operator 原理与实践
构建企业级监控平台系列(十五):Prometheus Exporter 原理与实践
构建企业级监控平台系列(十六):Prometheus Node Exporter 详解
构建企业级监控平台系列(十七):Prometheus Label 原理与实践
构建企业级监控平台系列(十八):Prometheus 数据查询语言 PromQL
构建企业级监控平台系列(十九):Prometheus 报警模块 AlertManager
构建企业级监控平台系列(二十):Prometheus Alertmanager 配置实现钉钉告警
构建企业级监控平台系列(二十一):Prometheus Pushgateway 详解
构建企业级监控平台系列(二十二):Prometheus 基于 K8S 服务发现详解
构建企业级监控平台系列(二十三):Prometheus 配置监控常用服务实践
构建企业级监控平台系列(二十四):Prometheus 配置 Grafana 展示与报警
构建企业级监控平台系列(二十五):Prometheus 高可用集群方案
构建企业级监控平台系列(二十六):Prometheus 高可用架构 Thanos 实践
构建企业级监控平台系列(二十七):Grafana 基础入门与部署
构建企业级监控平台系列(二十八):Grafana 仪表盘 DashBoard
构建企业级监控平台系列(二十九):Grafana Dashboard 变量
构建企业级监控平台系列(三十):Grafana Panel 面板和 Time series 时间序列
构建企业级监控平台系列(三十一):Grafana 添加动态参数详解
构建企业级监控平台系列(三十二):Grafana 可视化面板 Heatmap 与 Gauge
构建企业级监控平台系列(三十四):Grafana 数据可视化工具安装与应用
打造企业级 DevOps 自动化运维管理平台。
DevOps并不是凭空创造出来的一个概念,DevOps是Development和Operations的组合,是一种方法论,是一组过程、方法与系统的统称,用于促进应用开发、应用运维和质量保障(QA)部门之间的沟通、协作与整合。以期打破传统开发和运营之间的壁垒和鸿沟。
它也是有着历史的发展过程的。
简而言之,DevOps是继软件开发的瀑布模型、敏捷模型后的第三种软件开发的方法论,可以理解为:
- 第一阶段:瀑布模型
- 第二阶段:敏捷模型
- 第三阶段:DevOps
打造企业级自动化运维平台系列(二):DevOps、CI、CD、CT 详解
打造企业级自动化运维平台系列(三):DevOps 常用的软件工具
打造企业级自动化运维平台系列(四):Jenkins 基础入门与安装
打造企业级自动化运维平台系列(五):Jenkins 基本使用介绍
打造企业级自动化运维平台系列(六):Jenkins Pipeline 入门及使用详解
打造企业级自动化运维平台系列(七):Jenkins 部署 Springboot 应用实践
打造企业级自动化运维平台系列(八):Jenkins 部署前后端分离项目
打造企业级自动化运维平台系列(九):Jenkins 基于 K8s 的 DevOps 平台实践
打造企业级自动化运维平台系列(十):Gitlab Runner 实现 CI/CD 详解
打造企业级自动化运维平台系列(十一):微服务基础入门(概念与架构)
打造企业级自动化运维平台系列(十二):服务发现与配置管理平台 Nacos 详解
打造企业级自动化运维平台系列(十三):分布式的对象存储系统 MinIO 详解
打造企业级自动化运维平台系列(十四):容器管理工具 Rancher 详解
打造企业级自动化运维平台系列(十五):kubernetes 包管理工具 Helm 详解
打造企业级自动化运维平台系列(十六):服务网格 Istio 详解
打造企业级自动化运维平台系列(十七):链路追踪工具 SkyWalking 详解
打造企业级自动化运维平台系列(十八):influxDB、cAdvisor、Grafana
打造企业级自动化运维平台系列(十九):云服务器 ECS 入门(配置与使用)
打造企业级自动化运维平台系列(二十):云服务器 ECS 进阶(SLB/弹性伸缩)
介绍常用工具(命令工具、其它工具)相关的日常运维所需知识体系。
可以参阅专栏:Tools 去学习更多相关工具的原理与操作。
还可以进一步去了解一些后端的基础入门理论知识,通过熟悉上下游的知识体系,这样在工作中我们也不会那么容易被动,这就是运维为什么要不断学习的原因。
比如:了解一下关于Java后端技术、微服务架构,轻量级 Java开发框架Spring 等。
介绍企业面试经验、各类面试题详解等(面试题与面试经验总结分享),下面给大家列举了一些常见的面试题,更多关于企业面试题相关的知识学习,可以参考专栏:企业面试题集合。
学完这些内容这后,可以这么说,还是仅仅是开始,更多的还是要将所学的知识结合实际的生产环境,然后通过不断的实践去总结,慢慢的一点点去补充自己的整个知识体系的高墙,从而使之更坚固、更持久、更强大。
如有帮助,请点Star 支持!感谢你的关注与支持。
路虽远,行则将至!
事虽难,做则必成!
