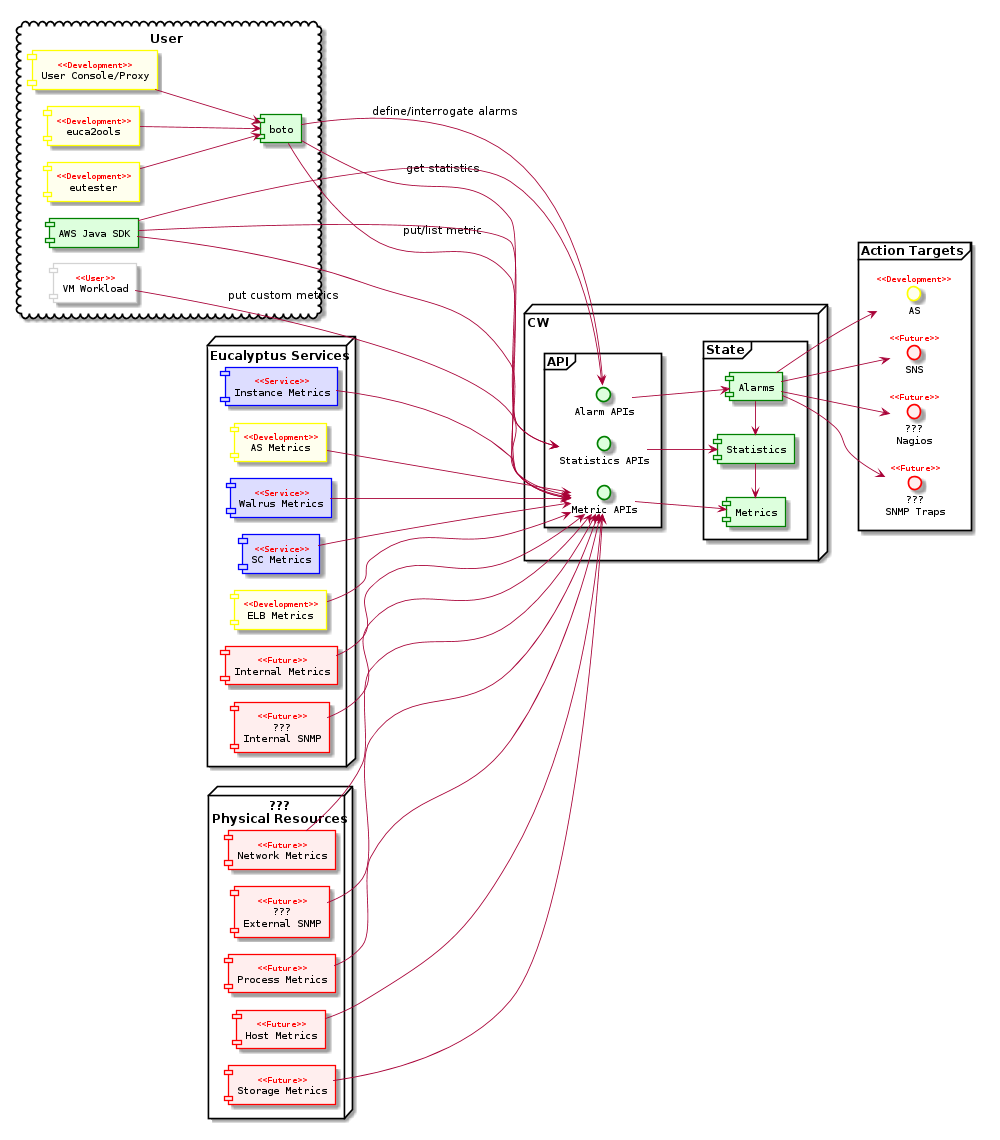
cloudwatch 3.3 spec
In terms of operations we have:
-
Metric Basics
- GetMetricStatistics
- ListMetrics
- PutMetricData
-
Alarms
- DeleteAlarms
- DescribeAlarms
- DescribeAlarmsForMetric
- PutMetricAlarm
- SetAlarmState
- DescribeAlarmHistory
-
Actions
- DisableAlarmActions
- EnableAlarmActions
- Represents a time-ordered set of data points.
-
Metrics are uniquely defined by:
- Name
- Namespace
- One or more dimensions
- Each data point has a time stamp
- And (optionally) a unit of measure
- When you request statistics, the returned data stream is identified by:
- Namespace
- Metric name
- Dimension
- And (optionally) the unit
- PutMetricData can be used to create a custom metric and publish data points for it.
-
Data points:
- can be added in any order (i.e., ordering is determined by time)
- can be added at any rate
- that are fully identical (duplicate values, time stamps, and units) are aggregated at statistic computation time.
- The retention interval determines the duration of the history of any kind of data point is stored: default two weeks of history.
-
Data points:
- Statistics are computed over a metric's data points during a given time window.
-
Namespaces names are strings defined when a metric is created
- These names are constrainted to:
- Valid XML characters
- Fewer than 256 characters in length.
- Typically containing the alphanumeric characters "0-9A-Za-z" plus "."(period), "-" (hyphen), "_" (underscore), "/" (slash), "#" (hash), and ":" (colon).
- Pre-defined namespaces follow the convention AWS/<service></service>, such as AWS/and AWS/ELB.
- There is no default namespace (a namespace must be specified for each data element).
- These names are constrainted to:
-
Dimension is a name/value pair that helps you to uniquely identify a metric.
- Adding a unique dimension in effect creates a new metric. They are not a separate entity -- they are an attribute.
- Internal services also attach dimensions to each metric.
- For internal metrics data points can be aggregated across dimensions.
- There is a limit on the number of dimensions for a metric: default ten.
- Each unique combination of dimensions is a separate metric.
-
Time stamps marks every metric data point.
- The time stamp must be within the retention interval defined above.
- The time stamp can be in the future by up to some time period: default one day.
- If not specified, a time stamp of the current time will be used when the data element is received.
- The time stamp is a dateTime object (complete date, plus hours, minutes, and seconds; http://www.w3.org/TR/xmlschema-2/#dateTime).
-
Units represent the unit of measure.
- A unit can be specified with custom metrics.
- Data published without a unit uses the None unit.
- Statistics requested without specifying a unit result in data points which share the same unit being aggregated together according to the given statistic request.
- Two metrics with different units will return a data stream for each unit separately.
-
Statistics are metric data aggregations over specified periods of time.
- Aggregations are made using:
- Namespace
- Metric name
- Dimensions
- Unit
- Within a given time period.
- Aggregations are made using:
- Defined statistics for a specified period of time is:
- Minimum: The lowest value observed.
- Maximum: The highest value observed.
- Sum: All values submitted for the matching metric added together.
- SampleCount: The count (number) of data points used for the statistical calculation.
- Average: The value of Sum / SampleCount during the specified period.
-
Time periods
- Each statistic represents an aggregation of the metrics data collected for a specified period of time.
- A period can be as short as one minute (60 seconds) or as long as two weeks (1,209,600 seconds).
- The minimum granularity for a period is one minute.
- You also specify the encompassing period, or start and end times that CloudWatch will use for the aggregation.
- The starting and ending points can be as close together as 60 seconds, and as far apart as two weeks.
- When you call GetMetricStatistics, you can specify the period length with the Period parameter. Two related parameters, StartTime and EndTime, determine the overall length of time associated with the statistics.
- The default value for the Period parameter is 60 seconds, whereas the default values for StartTime and EndTime give you the last hour's worth of statistics.
- The values you select for the StartTime and EndTime parameters determine how many periods GetMetricStatistics will return.
-
Aggregation in PutMetricData allows for samples (sets of data points) to be submitted along w/ the corresponding metric.
- Data points can have the same or similar time stamps.
- Data points for a metric that share the same time stamp, namespace and dimensions will return aggregated statistics about those data points.
- Multiple data points in the same PutMetricData call with the same time stamp.
- Multiple unrelated data points can also be published in one call.
- The size of a PutMetricData request is limited:
- default 8KB for HTTP GET
- default 40KB for HTTP POST
- PutMetricData request maximum data points per request: default of 20 data points.
- StatisticSets are pre-aggregated data sets: given the Min, Max, Sum, and SampleCount of a number of datapoints.
- Data points can have the same or similar time stamps.
- CloudWatch is especially useful because it helps you make decisions and take immediate, automatic actions based on your metric data.
- Alarms can automatically initiate actions on your behalf, based on parameters you specify.
- An alarm watches a single metric over a time period you specify, and performs one or more actions based on the value of the metric relative to a given threshold over a number of time periods.
- The action is a notification sent to an Amazon SNS topic or Auto Scaling policy.
- Alarms invoke actions for sustained state changes only.
- CloudWatch alarms will not invoke actions simply because they are in a particular state, the state must have changed and been maintained for a specified number of periods.
| Metric | Description | Units | Notes |
| CPUUtilization | The percentage usage of allocated CPU | Percent | |
| DiskReadOps | Completed read operations from all ephemeral disks available to the instance. | Count | |
| DiskWriteOps | Completed write operations to all ephemeral disks available to the instance. | Count | |
| DiskReadBytes | Bytes read from all ephemeral disks available to the instance. | Bytes | |
| DiskWriteBytes | Bytes written to all ephemeral disks available to the instance. | Bytes | |
| NetworkIn | The number of bytes received on all network interfaces by the instance. | Bytes | |
| NetworkOut | The number of bytes sent out on all network interfaces by the instance. | Bytes | |
| StatusCheckFailed | A combination of StatusCheckFailed_Instance and StatusCheckFailed_System that reports if either of the status checks has failed. Values for this metric are either 0 (zero) or 1 (one.) A zero indicates that the status check passed. A one indicates a status check failure. | Count | |
| StatusCheckFailed_Instance | Reports whether the instance has passed the instance status check in the last 5 minutes. Values for this metric are either 0 (zero) or 1 (one.) A zero indicates that the status check passed. A one indicates a status check failure. | Count | Status check metrics are available at 5 minute frequency and are not available in Detailed Monitoring. For a newly launched instance, status check metric data will only be available after the instance has completed the initialization state. Status check metrics will become available within a few minutes of being in the running state. |
| StatusCheckFailed_System | Reports whether the instance has passed the system status check in the last 5 minutes. Values for this metric are either 0 (zero) or 1 (one.) A zero indicates that the status check passed. A one indicates a status check failure. | Count | |
| Dimensions | |||
| Dimension | Description | ||
| AutoScalingGroupName | This dimension filters the data you request for all instances in a specified capacity group. An AutoScalingGroup is a collection of instances you define if you're using the Auto Scaling service. This dimension is available only for metrics when the instances are in such an AutoScalingGroup. Available for instances with Detailed or Basic Monitoring enabled. | ||
| ImageId | This dimension filters the data you request for all instances running this emi. Available for instances with Detailed Monitoring enabled. | ||
| InstanceId | This dimension filters the data you request for the identified instance only. This helps you pinpoint an exact instance from which to monitor data. Available for instances with Detailed Monitoring enabled. | ||
| InstanceType | This dimension filters the data you request for all instances running with this specified instance type. This helps you categorize your data by the type of instance running. For example, you might compare data from an m1.small instance and an m1.large instance to determine which has the better business value for your application. Available for instances with Detailed Monitoring enabled. |
| Metric | Description | Units | Notes |
| VolumeReadBytes/VolumeWriteBytes | The total number of bytes transferred in the period. | Bytes | |
| VolumeReadOps/VolumeWriteOps | The total number of operations in the period. | Count | |
| VolumeTotalReadTime/VolumeTotalWriteTime | The total number of seconds spent by all operations that completed in the period. If multiple requests are submitted at the same time, this total could be greater than the length of the period. For example, say the period is 5 minutes (300 seconds); if 700 operations completed during that period, and each operation took 1 second, the value would be 700 seconds. | Seconds | |
| VolumeIdleTime | The total number of seconds in the period when no read or write operations were submitted. | Seconds | |
| VolumeQueueLength | The number of read and write operation requests waiting to be completed in the period. | Count | |
| VolumeThroughputPercentage | Used with Provisioned IOPS volumes only. The percentage of I/O operations per second (IOPS) delivered out of the IOPS provisioned for an EBS volume. Provisioned IOPS volumes deliver within 10 percent of the provisioned IOPS performance 99.9 percent of the time over a given year. | Percent | During a write, if there are no other pending I/O requests in a minute, the metric value will be 100 percent. Also, a volume's I/O performance may become degraded temporarily due to an action you have taken (e.g., creating a snapshot of a volume during peak usage, running the volume on a non-EBS-optimized instance, accessing data on the volume for the first time). |
| VolumeConsumedReadWriteOps | Used with Provisioned IOPS volumes only. The total amount of read and write operations consumed in the period. | Count | |
| Dimensions | |||
| The only dimension that Amazon EBS sends to Amazon CloudWatch is the Volume ID. This means that all available statistics are filtered by Volume ID. |
| Metric | Description | Units | Statistics | Notes |
| Latency | Time elapsed after the load balancer receives a request until it receives the corresponding response. | Seconds | Minimum, Maximum, Average, and Count | |
| RequestCount | The number of requests handled by the load balancer. | Count | Sum | |
| HealthyHostCount | The number of healthy instances registered with the load balancer in a specified Availability Zone. Hosts that have not failed more health checks than the value of the unhealthy threshold are considered healthy. When evaluating this metric, the dimensions must be provided for LoadBalancerName and AvailabilityZone. The metric represents the count of healthy instances in the specified Availability Zone. Instances may become unhealthy due to connectivity issues, health checks returning non-200 responses (in the case of HTTP or HTTPS health checks), or timeouts when performing the health check. To get the total count of all healthy hosts, this metric must be retrieved for each registered Availability Zone and then all the metrics need to be added together. | Count | Minimum, Maximum, and Average | |
| UnHealthyHostCount | The number of unhealthy instances registered with the load balancer in a specified Availability Zone. Hosts that have failed more health checks than the value of the unhealthy threshold are considered unhealthy. When evaluating this metric, the dimensions must be provided for LoadBalancerName and AvailabilityZone. The metric represents the count of unhealthy instances in the specified Availability Zone. Instances may become unhealthy due to connectivity issues, health checks returning non-200 responses (in the case of HTTP or HTTPS health checks), or timeouts when performing the health check. To get the total count of all unhealthy hosts, this metric must be retrieved for each registered Availability Zone and then all the metrics need to be added together. | Count | Minimum, Maximum, and Average | |
| HTTPCode_ELB_4XX | Count of HTTP response codes generated by Elastic Load Balancing that are in the 4xx (client error) series. | Count | Sum | |
| HTTPCode_ELB_5XX | Count of HTTP response codes generated by Elastic Load Balancing that are in the 5xx (server error) series. Elastic Load Balancing may generate 5xx errors if no back-end instances are registered, no healthy back-end instances, or the request rate exceeds Elastic Load Balancing's current available capacity. This response count does not include any responses that were generated by back-end instances. | Count | Sum | |
| HTTPCode_Backend_2XX | Count of HTTP response codes generated by back-end instances that are in the 2xx (success) series. | Count | Sum | |
| HTTPCode_Backend_3XX | Count of HTTP response codes generated by back-end instances that are in the 3xx (user action required) series. | Count | Sum | |
| HTTPCode_Backend_4XX | Count of HTTP response codes generated by back-end instances that are in the 4xx (client error) series. This response count does not include any responses that were generated by Elastic Load Balancing. | Count | Sum | |
| HTTPCode_Backend_5XX | Count of HTTP response codes generated by back-end instances that are in the 5xx (server error) series. This response count does not include any responses that were generated by Elastic Load Balancing. | Count | Sum | |
| Dimensions | ||||
| Dimension | Description | |||
| LoadBalancerName | Limits the metric data to instances that are connected to the specified load balancer. | |||
| AvailabilityZone | Limits the metric data to load balancers in the specified Availability Zone. |
tag:rls-3.3