User-friendly, type safe, runtime efficient tooling for working with tabular data deserialized from comma-separated values (CSV) files. The type of each row of data is inferred from data, which can then be streamed from disk, or worked with in memory.
We provide streaming and in-memory interfaces for efficiently working with datasets that can be safely indexed by column names found in the data files themselves. This type safety of column access and manipulation is checked at compile time.
For comparison to working with data frames in other languages, see the tutorial.
To play with various
demos, I
recommend working in a cabal sandbox, and not installing the
executables associated with each demo.
$ cabal sandbox init
$ cabal install --dependencies-only -f demos
$ cabal configure -f demos
$ cabal run getdata
$ cabal run plot
The getdata program downloads data sets used by the plot and
plot2 demo programs. Feel free to download those files manually;
they are linked from the source for the demo programs that use them.
You can also explore the demos interactively by specifying a build
target to cabal repl,
$ cabal repl plot
The benchmark shows several ways of dealing with data when you want to perform multiple traversals.
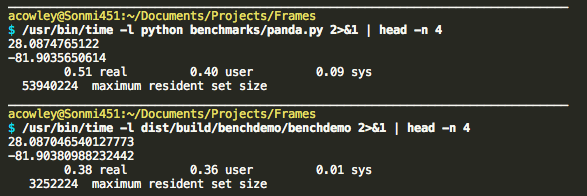
Another demo shows how to fuse multiple passes into one so that the full data set is never resident in memory. A Pandas version of a similar program is also provided for comparison.
This is a trivial program, but shows that performance is comparable to Pandas, and the memory savings of a compiled program are substantial.