This repository implements a framework for evaluating different feature selection methods. We provide a baseline permutation importance [2] method in our pipeline (using implementation from sklearn) as well as implementations of two more recent methods: Normalised Iterative Hard Thresholding [1] and Simultaneous Feature and Feature Group Selection through Hard Thresholding [3]. The pipeline allows to perform evaluation on both synthetic and real data.
To reproduce results presented in the repository you have to make sure Kedro is installed.
From the root of the project run the following commands in the terminal
to reproduce Test 1:
kedro run --pipeline synth_pi
kedro run --pipeline synth_iht to reproduce Test 2:
kedro run --pipeline synth_pi --params poly_degree:3
kedro run --pipeline synth_iht --params poly_degree:3to reproduce Test 3:
kedro run --pipeline synth_pi --params noise_std:6
kedro run --pipeline synth_iht --params noise_std:6to reproduce Test 4:
kedro run --pipeline synth_pi --params redundancy_rate:0.75
kedro run --pipeline synth_iht --params redundancy_rate:0.75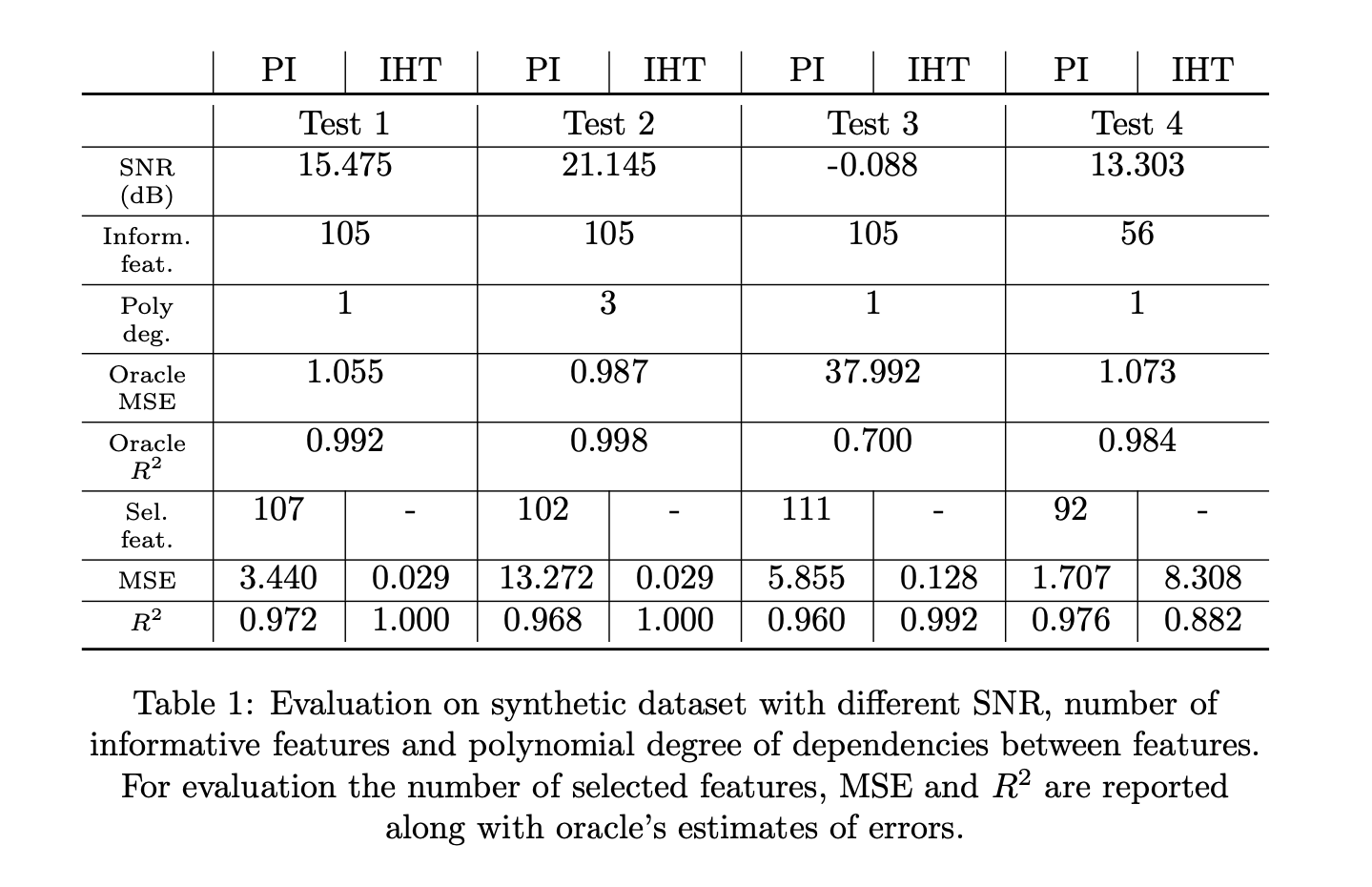
Permutation importance is an approach to compute feature importances for anyblack-box estimator by measuring the decrease of a score when a feature is notavailable. Permutation importance is calculated after a model has been fitted (i.e., the estimator is required to be a fitted estimator compatible with scorer).
This method contains the following steps:
- A baseline metric, defined by scoring, is evaluated on a data set defined by the X, where X can be the data set used to train the estimator or ahold-out set;
- A feature column from the validation set is permuted and the metric is evaluated again;
- The difference between the baseline metric and metric from permutating the feature column is the permutation importance.
Parameters can be described as follows [2]:
- estimator - Fitted estimator compatible with scorer
- X - Data on which permutation importance is compute
- y - Targets (in case of supervised) or Non (in case of unsupervised)
- scoring - Scorer
- nrepeats - Number of feature permutation times
- njobs - Number of jobs for parallel run. Calculation is conducted by computing permutation score for each column, parallelized over the columns.
- randomstate - Pseudo-random number generator to control the permutations of each feature
- sampleweight - Sample weights for scoring.
The mean of feature importance shows the degree of model performance accuracy deterioration with a random shuffling, and the standard deviation shows the variation of performance from one reshuffling to the next. Cases of negative values for permutation importances are possible, especially among small datasets; however, they merely depict the insufficiency of dataset, as they point out that "noisy" data happened to be more accurate than the real data, i.e. there is some random chance distortion.
This method is most appropriate for computing feature importances with a reasonably limited number of columns (features), as it can be resource-intensive.
The algorithm searches for starting from
by applying the iterative procedure below where
is a non-linear operator that sets all but the top-k largest elements by their magnitude to zero and
is computed adaptively as described in [1].
Pros:
- Gives theoretical guarantees on convergence to a local minimum of the cost function
- Doesn't depend on the scaling of the design matrix
Cons:
- Theoretical guarantees on convergence exist only if
that satisfies restricted isometry property
The algorithm employs the iterative procedure below where is the objective loss function,
is found by line search and
stands for Sparse Group Hard Thresholding that is solved by dynamic programming as described in [3].
Pros:
- Line search on each iteration can be significantly sped up
- Gives theoretical guarantees on convergence to a local minimum of the cost function that is at least within
radius from globally optimal solution
for a certain constant
Cons:
- Theoretical guarantees on convergence exist only if
To evaluate performance of different methods we plan to employ the protocol from [3]. Namely, we're going to report the number of selected features, feature groups (for ISTA with SGHT [3]) and mean squared error.
We also plan to study the influence of the noise on the performance of each method. Following [1] we aim to generate data with a certain signal-to-noise ratio (SNR) and compare the estimation of SNR to an oracle to which the noise values are known.
As proposed in [3] for generating synthetic data for examination of methods we're going to use the linear model where the design matrix and the noise term follows normal distribution and the ground truth parameters being partitioned into 20 equally sized groups. In this research, we intend to consider several kinds of grouping structures. The goal is to obtain an accurate (in terms of least squares) estimator of the parameters that preserves the grouping structure, given only the desing matrix and the observations.
Motivated by [3] we intend to study the algorithms on the Boston Housing data set. The original data set is used as a regression task, containing 506 samples with 13 features. Up to third-degree polynomial expansion is applied on each feature to account for the non-linear relationship between variables and response. As a next step we split the data into the training set (approximately 50%) and testing set. The parameter settings for each method are properly scaled to fit the data set. We intend to use a linear regression model for training and testing with the evaluation protocol described above.
In this research, we split responsibilities as follows:
- Viacheslav Pronin will implement the Normalized Iterative Hard Thresholding method and study the algorithms on the real data.
- Konstantin Pakulev will apply the Simultaneous Feature and Feature Group Selection through Hard Thresholding method and focus on the examination of algorithms on the synthetic data.
Both researchers will work on the metrics section and provide the evaluation of methods’ accuracy, as well as conclusions and recommendations for further research.
[1] T. Blumensath and M. E. Davies. Normalized iterative hard thresholding:Guaranteed stability and performance.IEEE Journal of Selected Topics inSignal Processing, 4(2):298–309, 2010.
[2] Leo Breiman. Random forests.Machine Learning, 45(1):5–32, 2001.
[3] Shuo Xiang, Tao Yang, and Jieping Ye. Simultaneous feature and feature group selection through hard thresholding. In Proceedings of the 20th ACMSIGKDD International Conference on Knowledge Discovery and Data Min-ing, KDD ’14, page 532–541, New York, NY, USA, 2014. Association for Computing Machinery.