This is a complete guide for the swap-face algorithm known as deepFakes.
The goal of this project is education purpose. The deepFakes project got viral on the internet (with all the moral implication that come with it), but very few people really understand how it works. In fact, it is relatively simple>
The youtube video about deepfake made by Siraj Raval also gives a good insight about deepfakes, and I invite you to check its video.
The coding challenge presented in deepFakes by Siraj Raval.
This coding challenge is to train a swap-face algorithm.
The submission files are the three Ipython Notebooks:
1. Training data generation.ipynb
2. Train.ipynb
3. Prediction.ipynb
I was born in 1988. So for me, James Bond has always been Pierce Brosnan (even Daniel Craig doesn't play that bad). As a result, today we will learn how to train a network that swap the face of Daniel Craig and replace it by Pierce Brosnan. The result can be seen below.

Deepfake is implemented as an autoencoder. The face of the actor 1 is cropped and aligned to his face. Then the autoencoder learns how to encode and decode (reconstruct) the face. The goal here is to minimize the reconstruction error.
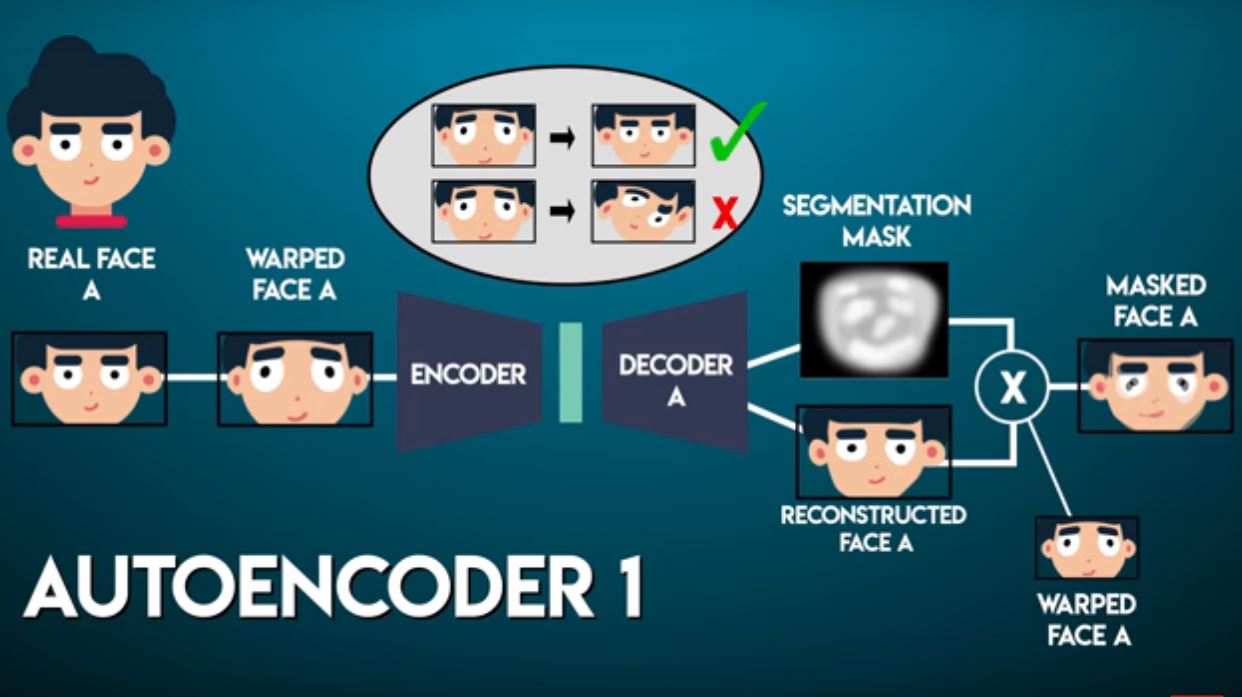
The face of the actor 2 is cropped and aligned to his face. Then the autoencoder learns how to encode and decode (reconstruct) the face. The goal here is to minimize the reconstruction error. The interesting part is that the encoder is the same for actor 1 and 2.

The goal is to find a mathematical function that for a face of the actor 1, outputs a face that looks like the actor 2.
Note: these images don t belong to me and comes from the animation in the youtube video about deepfake made by Siraj Raval
Auto encoder wants to find a function f(x) ≈ xwhere x is your image (here, the size is arbitrary chosen to be 64 by 64 with 3 channels (RBG) ). For that, we have an encoder which goal is to encode your image in a smaller representation (Here, we choose 8 by 8 with 512 channels ), and a decoder which goal is to use this representation and get back the original images.
You could see an autoencoder as WinZip. You have a folder that you want to compress in zip. First, WinZip will parse your folder and find out some pattern (some data that are more useful than others) then it will take advantage of this information to encode these data on less bit. Finally, you end up with a zip file with the same information by encoded differently. Later if you give this file to a friend this friend needs to decode the zip file in order to read its content. We call that lossless compression (you don't lose information). In the case of autoencoder, it does a kind of lossy compression (the data that you get back at the end is an approximation of the initial data).
The goal of an autoencoder is to find the function f(x) = decoder(encoder(x)) ≈ x that approximates the best. For that (in contrast of WinZip or WinRAR) it takes advantage of the nature of x. (1) x is an image. (2) x shows the same face but with different angle, lightening condition ... (1) often means that you might need to use convolution operations. (2) implies that you need to decompose your face into its atomic components, such as the shape of the noise, the shape of the smile, the wrinkle ...
You should see the output of the encoder as 512 different images of 8 by 8. Each of these images gives some insight about the noise shape, the ear shape ... These features represent the persons face and will be used by the decoder to reconstruct the image.
The authors of the original implementation contacted me, and mentioned an important point about the architecture of this tool:
- In the original deepfakes' architecture, there is no mask segmentation. The only output is reconstructed image.
- The interesting (and smart) parts of deepfakes' algorithm are the usage of warped image as input and shared-weights encoder. The encoder get update information (backprop. information) from both two decoder_A and B. But on the contrary, decoder_A never trained on face B for reconstruction (and vise versa for decoder_B). In other words, the encoder is able to encode both face A and B into good embedding, but decoder A/B can only generates face A/B respectively from the given embedding.
- To swap face of person B to person A in test time, we feed face B in to encoder to get the embedding, and then feed the embedding into decoder A (not decoder B) to get a face B which is face A look-alike. The reason of such method works is that the autoencoder_A (i.e., encoder + decoder_A) treats face B as if its a warped A, so it "reconstruct" face B into a face A look-alike. If we did not train the autoencoder using warped images, it might not able to "treat face B as if its a warped A".
In contrast to the base version of Deepfakes, we provide a very convenient way to speed up the training process via transfer learning. The idea is to load the weight of a pre-trained network (for the same network configuration but for another face pair such as Donald ump and Nicolas Cage) These weights are used as a starting point to learn new weight. The network will, therefore, converge faster than if it would be trained from scratch. \n",
More advanced technique exists to apply transfer learning to autoencoder such here
Associated with this project, there is a file called "floyd_requirements.txt" which lists all libraries that need to be installed before to run the application.
You install them with sudo pip install
If you have any problem. Feel free to contact me or post an issue.
The version I release can be run on any computer or virtual machines (as long as the requirement are installed).
The nice thing is that you can also run it easily on floydhub (which is a cloud GPU company). Please note that I don't work for this company (just that you often need a good GPU to train such model)
You can download the weights there
| Input | Output |
|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
The goal of this project is education purpose. With AI area, it becomes easy for anyone to fake video, pictures, and news. As someone smart said one day: "With great power comes great responsibility".
Autoencoder is great tool for producing images which respect the probability distribution of the original ones. However, I believe that Generative Adversarial Networks (such as cycle-gan) remains a great way to train autoencoder, and surpass the generation capability of standard autoencoder.
This tutorial aims to help other to understand the value of DeepFakes algorithm. However, if you have additional questions, feel free to open an issue. I want to make this guide as complete as possible and I will add to it any of your comment that would make it more understandable and detailled.