For me, the Artificial Intelligence is like a passion and I am trying to use it to solve some daily life problems. In this tutorial/project, I want to give some intuitions to the readers about how deep learning is actually working. In this tutorial, we will talk about a class of deep learning algorithms called "Generative Adversarial Network". This category of networks is relatively new and the logic behind it often misunderstood.
During my leisure time, I like to read mangas. However, most of them are issued in black and white. Famous mangas, such as "one piece" have been colorized. However, such digital colorization process is long and tedious. In addition, even for mangas such as "one piece", the digital colorization process falls far behind the actual manga publication. Is it possible to automatize this colorization process? This is the question we will try to answer via this project.

The challenge I intend to solve in this project is to use AI to learn a function that maps an input image in black and white (original manga) to an output image in color (the same manga digitally colorized). This AI should be able to identify different characters, objects (clothing...), environments (sea, mountain ...) and infer some color for the manga page. Note the colors should be consistent between manga strip boxes and between pages.
In order to solve the aforementioned problem, we should use a category of Artificial Intelligence algorithms called Generative model. We mainly distinguish 2 categories of deep learning model:
- Discriminative model, which given an input (image, text, data ...) maps its probability distribution to a given class. Generally speaking, your model will be trained to observe some input data and extract some patterns, which will be used to classify this data. More formally, we can say that classification models amplify aspects of the input that are important for discrimination and suppress irrelevant variations.
- For example, let's say I want to build an AI that identifies numbers(1, 2, 3 ...). We will feed our discriminative model with raw data and it will automatically discover the representations/patterns in the image that are needed to classify this input image as a 1, 2, 3 ...
- For more information, feel free to read Deep learning - Nature
- Generative Model learns a data distribution using unsupervised learning (learning without label) and is able to generate some sample that follows the same data distribution. Less formally, we can say that Generative Models discovers some patterns in input images (without guidance - label), and is able to generate some new data that follow the same design pattern rule.
- For example, let's say I want to build an AI that generates handwritten digit (1, 2, 3, 4 ...). We will feed our Generative Model with raw data and it will automatically discover the representations/patterns in the image that are needed to generate new handwritten digits (for example, the shape of a 1 ...)
- For more information, feel free to read Deep Generative Models - towards data science
For solving our problem we need to generation digitally colorized image which follows some design pattern rules (mainly esthetic rules). In addition, we don't want to teach our model manually which rules are important. We want our AI to discover them automatically, in an unsupervised fashion way. As a result, I choose to use Generative Model for that task.
Two of the most commonly used and efficient approaches are Variational Autoencoders (VAE) and Generative Adversarial Networks (GAN). In this tutorial, we mainly focus on Generative Adversarial Networks, which tends to focus a bit more on the realism of the output image.
Before to start coding, let's understand together the logic behind GANs. Generative Adversarial Networks is based on the idea that complex representations/pattern can be found by AI via the confrontation of two adversarial AIs. It is quite easy to understand that the police needs constantly improve itself as counterfeiter use more and more advanced technique to counterfeit money.
GANs are constituted of two networks:
- A generator, whose role is to generate new data instances.
- A discriminator, whose role is to evaluate their realism. It answers the question "Is this image a true or a fake instance? Does this image belong to the original training set? "
In the previous example, the counterfeiter (the generator) generates counterfeit money. Then, the generator passes the image of counterfeit money to the discriminator. It does so in the hopes that it will be deemed authentic, even though it is fake. The goal of the generator is to generate passable counterfeit money, to lie without being caught. The goal of the discriminator is to identify images coming from the generator as fake.
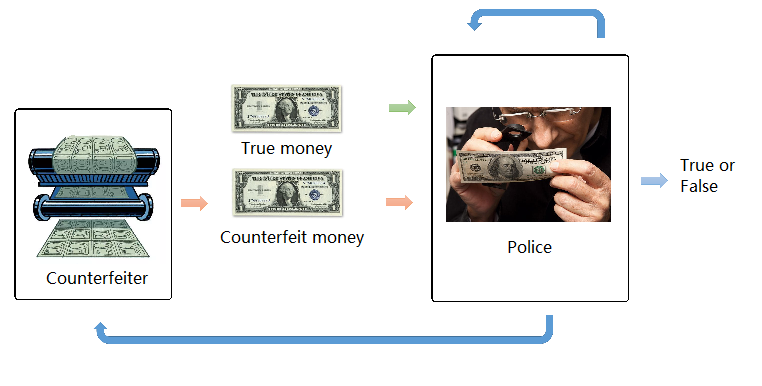
The output of the discriminator gives a feedback to the generator. As result, if you wait long enough, the generator will become very good to generate fakes that look like a true one and the discriminator will become very good at spotting fakes.
For this project/tutorial, we need original images of manga in Black/White and images of manga that have been digitalized and colorized by a human. Any manga is fine as long as the training set is large enough. For the purpose of this experiment, we pick the manga One piece. The main reason behind this choice is that this manga exists for more than 20 years and the fan community is quite large. As a result, it is quite easy to find a dataset of scans in Black/White and their colored version.
For copyright purpose, I won't make these 2 datasets available. I like One Piece as manga, and I do not support the illegal scan. The goal of this project is to share my task for AI. If you like One Piece, please buy the original book.
We want to find a non-linear function that maps an input image (the scan of one piece in Black/White) to an output image (the digitally colorized version of the same scan).
One problem is that the Black/White version and the digitally colorized version cannot easily be paired. For instance, only some of the important scans have been colorized.
An easy approach is to converts the scan from RGB to Grayscale. Another approach is to converts the scan from RGB to lab colorspace. However, these approaches forget that the colorization step often requires to slightly modify some line of the original scan. Doing it in that way would prevent our AI to generalize to new scans. More formally, the Grayscale scan wouldn't have the same probability distribution as the original B/W scan.
Instead, we decided to use train an AI without any paired data. This task is harder that with paired data (pix2pix), but allows our network easily generalize to new scans.
The research fields of GANs is very dynamic and there are many works that are published every day. I advise the reader to look for the GANs architecture that fit its needs. For this project, we use the Cycle-Gan architecture. This network is very efficient for generating mapping without paired input images, such as Black/White <-> color. For a deeper explanation, I advice you to watch the presentation of these paper which is very interesting.
This figure is a simplified overview of the algorithm. We start an input image in color (1). We use a generator A->B to get a B/W version (2). This process is repeated twice: Black/White -> color and color -> Black/White.
Finally, we use a generator B->A to get black the colorized version. The training aims to optimize 3 variables:
- The difference between the colorized scan in (1) and the one in (2). We generally talk about the norm L1
- The value output by discriminator A. It forces the network to generate realistic colorized scan
- The value output by discriminator B. It forces the network to generate realistic B/W scan

Most of the code has been borrowed from there. The main differences are:
- By default the Cycle-gan use visdom as a visualization tool, which is (I think) not as easy to operate as tensorboard. As a result, I replace visdom by tensorboardX, which enable tensorboard in a Pytorch environment.
Our network weights are available to download.
| Input (B/W) | Output (color) |
|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Note: the last image comes from the last scans which were published only a few weeks ago
Mangas, such as One Piece, have a lot of different characters. Without paired data, our network learns to recognize them and draw them with similar aesthetic characteristics (same hair color ...). In addition, our network is able to make the correlation between a state of different characters (in middle of a fight, wounded ... ) and infers information, such as when a character is bleeding his blood need to be red.
If the AI has never seen a character, it will infer colors that look good (from the aesthetic point of view), but may not be the final choice of the author.
If you like you like this project, feel free to leave a star. (it is my only reward ^^)