
{kind=link}
💡 基于rasa框架的智能医疗机器人 💡
本项目仅供学习参考,转载请注明出处,不提供商业使用
联系方式 QQ:609751841 VX:LuoFanA_595💡 文件目录 💡
actions
|_____actions.py
|_____api
|_______answer_search.py 执行sql语句
|_______app.py 查询天气+闲聊的API
|_______question_parser.py 生成查询语句
|_______Spider_open.py 疑难杂症处理
|_______voice.py 语音识别
|_______asr.py 百度API语音识别
|_______tts.py 百度API语音合成
|_____data
|_____lookup_tables 实体扩展
|_____nlu.yml 定义意图
|_____rules.yml 规则
|_____stories.yml 故事
|_____voice_Friday robot语音回复文件
|_____voice_person 用户语音输入文件
|_____Medical_Spider_API
|_____Spider_open.py 实时获取结果
|_____nlu_corpus_process 语料数据格式处理
|_____models 训练模型
|_____config 组件等配置文件
|_____domain.yml
|_____medical.json 数据库所需数据
|_____endpoints.yml 外部消息服务对接的endpoints配置
|_____credentials.yml socket参数定义
|_____nlu_corpus_process lookups_table下增加语料文件处理code
|_____match_entity_extractor.py 实体识别
|_____model 模型文件
|_____RUN_Text_To_Voice_Friday.py 文本To语音实现
|_____RUN_Voice_To_Voice_Friday.py 语音To语音实现
|_____录音文件
|_____socketio_connector.py socket协议连接器
|_____requirement.txt 项目运行所需安装包
|_____build_medicalgraph.py 数据-->数据库 导入
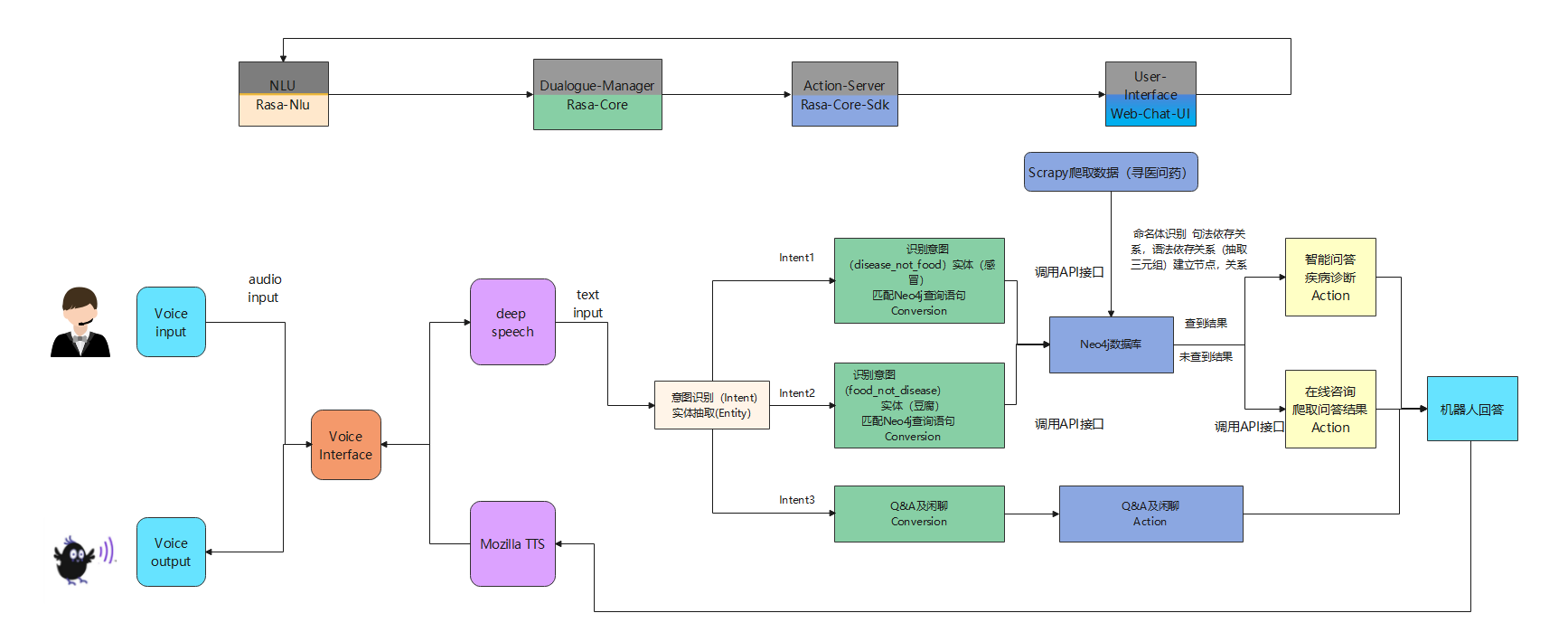
|_____rasa-voice-interface-master.zip 前端语音交互项目💡 技术架构 💡
# 1.创建项目虚拟环境---cmd执行命令
创建所需环境:conda create -n 环境名 python=3.7
激活环境:conda activate 环境名
# 2.neo4j图数据库的安装方法CSDN自查即可
# 3.项目所需安装包已打包在requirements.txt中
Terminal终端命令执行:pip install -r requirements.txt 即可安装
# 关与rasa X版本匹配问题解决方法如下(rasaX无响应)
https://luofan595.blog.csdn.net/article/details/121145483
# 关于py2neo-2020.1版本无法下载问题
1. 可以直接pip install py2neo,无需指定版本号
2. neo4j连接方法更改,例如:
graph = Graph("http://localhost:7474/", auth=("neo4j", "neo4j"))# 此项目主要实现了前端语音交互功能
1.
rasa-voice-interface中node及npm的安装教程参考以下链接
https://blog.csdn.net/LuoFan_A/article/details/120053319
2.
# 安装包及运行文档-百度网盘链接
链接:https://pan.baidu.com/s/1apR6z7x5U2Ed-Ff5FrrCew 提取码:yh4b# config.yml文件中可自定义参数
Terminal终端命令执行:rasa train# 在运行前 先启动actions服务
Terminal终端命令执行:rasa run actions --actions actions.actions
Terminal终端输入 rasa shell
Terminal终端输入 rasa shell --debug运行方式一 Run_Text_To_Voice-Friday.py
# 在运行前 先启动actions服务
Terminal终端命令执行:rasa run actions --actions actions.actions
# 运行Run_Text_To_Voice-Friday.py文件开启(文字到语音)对话模块运行方式二 Run_Voice_To_Voice-Friday.py
# 在运行前 先启动actions服务
Terminal终端命令执行:rasa run actions --actions actions.actions
# 运行Run_Voice_To_Voice-Friday.py文件开启(语音到语音)对话模块
# 此功能可直接与Friday语音交互rasa语音交互可视化界面运行
# 1.单独打开rasa-voice-interface项目 Terminal执行命令:npm run serve 启动html界面
# 2.在rasa项目下 多开Terminal窗口依次执行以下命令
(1)运行actions: rasa run actions --actions actions.actions
(2)用端口将文件映射到本地:python -m http.server 8888
(3)docker容器启动:docker run -p 8000:8000 rasa/duckling
(4)开启rasa项目:rasa run --debug --endpoints endpoints.yml --credentials credentials.yml --enable-api本项目完成了从无到有,以垂直网站为数据来源
构建起以rasa框架为主题架构,以疾病诊断为中心的智能医疗问答robot
数据使用crapy框架爬取寻医问药网构建对应实体关系及属性
项目采用知识图谱技术搭配neo4j图数据库实现对数据的存储
在导入数据库中发现之前编写的代码速度较慢,我们对此进行改进
实现快速匹配及批量导入数据库的方法大大缩短了所需时间
数据库中实体规模4.4万,实体关系规模29.2万
并围绕医疗数据,搭建起了一个可以回答18类问题的自动问答系统
在遇到数据库中没有存储到的数据我们采用优质医疗问答网站
实时爬取网站点赞评论数最多的专家建议,并返回给用户
后期以百度语音API接口实现语音识别及语音交互的功能
通过百度语音API接口本项目实现了语音对语音的单独文件开发
同时也实现了通过搭配rasa官网语音识别项目框架+百度语音API接口共同实现语音识别可视化
以上内容的实现可以使用户更方便的与robot进行交互
本项目功能拓展除了语音交互之外增加了智能聊天功能
智能聊天功能中拓展分类:天气查询 笑话分类 歌词查询 数学计算等丰富功能
本项目还有不足:关于疾病的起因、预防等实际返回的是一大段文字
这里其实可以引入事件抽取的概念,进一步将原因结构化表示出来。这个可以后面进行尝试
项目总耗时26天
如有朋友有想法加入功能拓展,可联系仓库管理员或联系本人[email protected]中国科学院刘焕勇老师图谱项目-QASystemOnMedicalKG
https://github.com/liuhuanyong/QASystemOnMedicalKG
数据来源网站-寻医问药网
https://www.xywy.com/
百度语音API
https://cloud.baidu.com/campaign/experience/index.html?track=cp:nsem|pf:PC|pp:nsem-liuliang-youzhi-pinpaici|pu:pinpaici-mianfei|ci:|kw:10293710
天气查询API
http://api.qingyunke.com/api.php?key=free&appid=0&msg=关键词
专家诊断建议
https://www.120ask.com/
rasa官方文档
https://rasa.com/docs/rasa/
#rasa官方语音识别项目及文档
https://rasa.com/blog/how-to-build-a-voice-assistant-with-open-source-rasa-and-mozilla-tools/
https://github.com/RasaHQ/rasa-voice-interface
1.如果你的电脑还没有安装Rasa,官网的安装指南在这里
https://rasa.com/docs/rasa/installation/
2.如果你想快速开始,查看下面链接
https://rasa.com/docs/rasa/playground
3.如果你的Rasa还是1.x,然后你想迁移到2.x,你可以查看下面的这些链接
https://rasa.com/docs/rasa/migration-guide#rasa-110-to-rasa-20
https://www.jianshu.com/nb/48166907
4.如果是Rasa 2.0 to Rasa 2.1,查看这里
https://rasa.com/docs/rasa/migration-guide#rasa-20-to-rasa-21
5.如果你想了解Rasa文档中的术语,可以查看Rasa词汇表
https://rasa.com/docs/rasa/glossary
6.如果你想紧追Rasa官方的最新博客,可以查看这里,Rasa官方的博客很有价值,很多功能都会在这里以Demo的形式进行实现
https://rasa.com/blog/
7. 如果你想从整体上了解Rasa2.x的所有数据格式,查看下面的链接
https://rasa.com/docs/rasa/training-data-format
8.如果你想详细了解训练NLU数据,查看这里
https://rasa.com/docs/rasa/nlu-training-data
9.如果你想详细了解Stories数据,查看这里
https://rasa.com/docs/rasa/stories
10.如果你想详细了解Rules数据,查看这里
https://rasa.com/docs/rasa/rules
11.如果你想了解Domain文件里都有什么,每一项代表什么意思,是什么格式,一定反复阅读下面链接的内容
https://rasa.com/docs/rasa/domain
12.如果你想实现功能复杂且强大的聊天机器人,那你就要不断修改你的config文件,需要掌握下面链接里的内容
https://rasa.com/docs/rasa/tuning-your-model
13.这里面具体包括了
1.1 如何选择管道(How to Choose a Pipeline)
合理的初始化管道
组件的生命周期
进行多意图分类
不同管道的比较
https://rasa.com/docs/rasa/tuning-your-model#how-to-choose-a-pipeline
1.2 选择正确的组件(Choosing the Right Components)
Tokenization
Featurization
Intent Classification / Response Selectors
Entity Extraction
https://rasa.com/docs/rasa/tuning-your-model#choosing-the-right-components
1.3 处理类别不平衡(Handling Class Imbalance)
https://rasa.com/docs/rasa/tuning-your-model#handling-class-imbalance
1.4 配置Tensorflow(Configuring Tensorflow)
优化CPU性能
优化GPU性能
https://rasa.com/docs/rasa/tuning-your-model#configuring-tensorflow