After first case of Sars-CoV-2 virus was reported in Kenya, the Ministry of Health under the government of Kenya, in conjuction with the World Health Organization, took measures to curb the spread of the virus in the country. Such measures included, equipping and building ultra modern labs for testing and research purposes. One of the labs given this mandate by the government was Covid-19 Testing and Reaserch Center at the Institute of Primate Research. The lab was tasked to test using Real Time PCR machine, for diagnosis of Covid-19 disease, and for tracking the variants bioinformatics skills were utilised to track the spread and emergence of the variants in the country.
For identification of various clades, and variants we will use actual raw dataset from the Institute to create a consensus genome and run the various consensus genome through Nextclade to find out our clades and mutations present.
This read me assumes familiriaty with Linux commands, and you have already installed all the necessary tools required for the next steps to begin. For our raw datasets, you will be provided during the workshop, together with the reference genome.
- We will begin by first activating our environment.
conda activate cov-analysis
- First let us view the quality of our data. We do this by using the command
fastqc *fastq.gz
This creates a html file that you can view it by opening it to the browser. Example of such result can be seen down below.
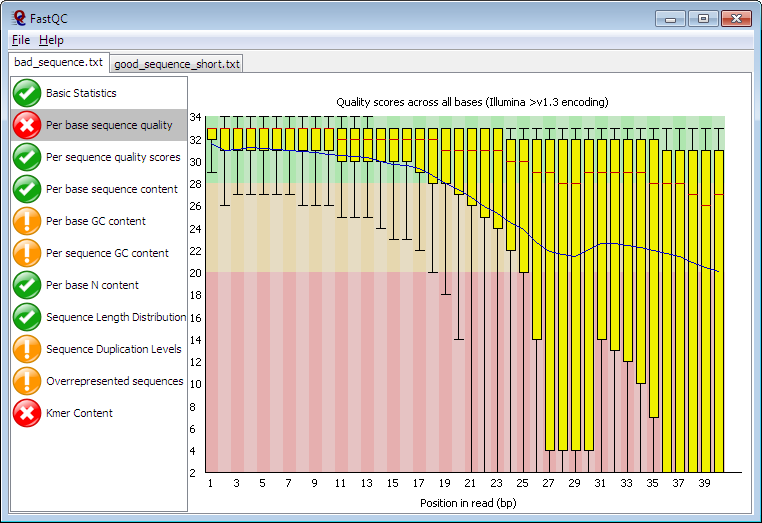
- After determining the quality of our sequences, next we proceed to trimming adapters and bad sequences (sequences that have a score of less than 30), and we remain with clean data that can undergo further down stream processes. Since our data is from illumina sequencer, we will use trimmomatic tool to cut illumina adapters together with other bad sequences.
trimmomatic PE -threads 4 raw_data/R1.fastq.gz R2.fastq.gz raw_data/R1_pair.fastq R1_unpair.fastq R2_pair.fastq R2_unpair.fastq ILLUMINACLIP:/path to our adapters.fa:2:30:10 LEADING:3 TRAILING:3 SLIDINGWINDOW:4:15 MINLEN:70
After trimming you can view the result of the trimmed data, by using the fastqc command.
- Next after trimming we need to map our reads to our reference genome. To achieve this we use the Burrow-Wheeler Aligner Maximal Exact Match algorithm or bwa mem in short, to map our trimmed fastq files against our reference Sars-CoV-2 genome. The output is then piped into samtools as input to sort the alignments, which are then output as bam files.
bwa mem -t 4 reference_genome.fasta *R1_pair.fastq *R2_pair.fastq | samtools sort | samtools view -F 4 -o *.sorted.bam
- Removing primers In this step we will use ivar, which is a computational package that contains functions broadly useful for viral amplicon-based sequencing. This tools is used to remove primers from our alignment map.
ivar trim -e *.sorted.bam -b ARTIC-V3.bed -p *.sorted.bam.primer.trim
- Sorting bams Before calling our consensus sequences, we have to sort our bams. It is achieved by using this command;
samtools sort *.primertrim.bam -o *.primertrim.bam.sorted
- Calling the consensus sequence Finally we create our consensus genome by using samtools. Samtools creates the read pileups which ivar uses to call consensus at a minimum depth quality of 10.
samtools mpileup -A -d 1000 -B -Q 0 --reference reference_genome.fasta *.primertrim.bam.sorted | ivar consensus -p *.consensus -n N -m 10
Note after building your consensus genome. You can use nextclade to Nexclade to classify your genome according to clades and pango lineages, as well as catalogue the nucleotide and amino acid mutations in your consensus genome compared to your reference genome.