##Table of Content ####1. C Language ####2. Operation System ####3. Network ####4. HTTP GET vs POST ####5. HTTP vs HTTPS ####5. DNS
[Understanding "extern" keyword in C] (http://www.geeksforgeeks.org/understanding-extern-keyword-in-c/)
- Declaration can be done any number of times but definition only once.
- “extern” keyword is used to extend the visibility of variables/functions().
- Since functions are visible through out the program by default. The use of extern is not needed in function declaration/definition. Its use is redundant.
- When extern is used with a variable, it’s only declared not defined, not allocate any memory.
- As an exception, when an extern variable is declared with initialization, it is taken as definition of the variable as well.
[Little and Big Endian Mystery] (http://www.geeksforgeeks.org/little-and-big-endian-mystery/)
Little and big endian are two ways of storing multibyte data-types ( int, float, etc).
-
In little endian machines, last byte of binary representation of the multibyte data-type is stored first.
-
On the other hand, in big endian machines, first byte of binary representation of the multibyte data-type is stored first.
-
In big endian, the most significant byte is stored at the memory address location with the lowest address This is akin to left-to-right reading order Little endian is the reverse: the most significant byte is stored at the address with the highest address
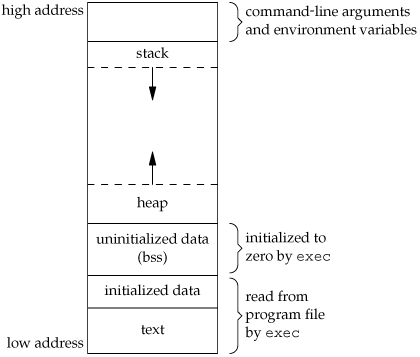
[Memory Layout of C Programs] (http://www.geeksforgeeks.org/memory-layout-of-c-program/)
A typical memory representation of C program consists of following sections.
- Text segment Often Read-Only
- Initialized data segment
- Initialized data segment, usually called simply the Data Segment.
- A data segment is a portion of virtual address space of a program, which contains the global variables and static variables that are initialized by the programmer.
- Not Read-Only
- Uninitialized data segment --> "bss" Segment
- For instance a variable declared static int i; would be contained in the BSS segment.
- For instance a global variable declared int j; would be contained in the BSS segment.
- Stack
- The stack area traditionally adjoined the heap area and grew the opposite direction; when the stack pointer met the heap pointer, free memory was exhausted.
- Stack, where automatic variables are stored, along with information that is saved each time a function is called. Each time a function is called, the address of where to return to and certain information about the caller’s environment, such as some of the machine registers, are saved on the stack.
- Heap
- The Heap area is managed by malloc, realloc, and free, which may use the brk and sbrk system calls to adjust its size (note that the use of brk/sbrk and a single “heap area” is not required to fulfill the contract of malloc/realloc/free; they may also be implemented using mmap to reserve potentially non-contiguous regions of virtual memory into the process’ virtual address space).
When Google released Chrome 41 and Chrome 42 beta earlier this month, the company said the former included “lots of under the hood changes for stability and performance” and that the latter was a “performance-focused build.” Today, the company has shared that users can expect a speed boost thanks to two new features: script streaming and code caching.
The former feature optimizes the parsing of JavaScript files while the latter helps speed up page loading. Both are designed to reduce the waiting time spent staring at a white screen, both on desktop and on mobile devices.
- Process is on Heap memory.
- Thread is on Stack memory.
- Stack is faster while heap is slower
- stackoverflow for stack while heap is for memory leak
#####Compare
| Stack | Heap |
|---|---|
| Stored in computer RAM just like the heap. | Stored in computer RAM just like the stack. |
| Variables created on the stack will go out of scope and automatically deallocate. | Variables on the heap must be destroyed manually and never fall out of scope. The data is freed with delete, delete[] or free |
| Much faster to allocate in comparison to variables on the heap. | Slower to allocate in comparison to variables on the stack. |
| Implemented with an actual stack data structure. | Used on demand to allocate a block of data for use by the program. |
| Stores local data, return addresses, used for parameter passing | Can have fragmentation when there are a lot of allocations and deallocations |
| Can have a stack overflow when too much of the stack is used. (mostly from infinite (or too much) recursion, very large allocations) | In C++ data created on the heap will be pointed to by pointers and allocated with new or malloc |
| Data created on the stack can be used without pointers. | Can have allocation failures if too big of a buffer is requested to be allocated. |
| You would use the stack if you know exactly how much data you need to allocate before compile time and it is not too big. | You would use the heap if you don't know exactly how much data you will need at runtime or if you need to allocate a lot of data. |
| Usually has a maximum size already determined when your program starts | Responsible for memory leaks |
#####Memory Leak A memory leak may happen when an object is stored in memory but cannot be accessed by the running code.
######Cause of Memory Leak
- Some low level C library is leaking
- Your Python code have global lists or dicts that grow over time, and you forgot to remove the objects after use
- There are some reference cycles in your app
#####Stack (Memory) When a function calls another function which calls another function, this memory goes onto the stack An int (not a pointer to an int) that is created in a function is stored on the stack #####Heap (Memory) When you allocate data with new() or malloc(), this data gets stored on the heap
The JVM divided the memory into following sections:
- Heap
- Stack
- Code
- Static
This division of memory is required for its effective management.
- The code section contains your bytecode.
- The Stack section of memory contains methods, local variables and reference variables.
- The Heap section contains Objects (may also contain reference variables).
- The Static section contains Static data/methods.
Of all of the above 4 sections, you need to understand the allocation of memory in Stack & Heap the most, since it will affect your programming efforts
- When a method is called , a frame is created on the top of stack.
- Once a method has completed execution , flow of control returns to the calling method and its corresponding stack frame is flushed.
- Local variables are created in the stack
- Instance variables are created in the heap & are part of the object they belong to.
- Reference variables are created in the stack.
####Thread and Process A process can be thought of as an instance of a program in execution Each process is an in- dependent entity to which system resources (CPU time, memory, etc ) are allocated and each process is executed in a separate address space One process cannot access the variables and data structures of another process If you wish to access another process’ resources, inter-process communications have to be used such as pipes, files, sockets etc
A thread uses the same stack space of a process A process can have multiple threads A key difference between processes and threads is that multiple threads share parts of their state Typically, one allows multiple threads to read and write the same memory (no processes can directly access the memory of another process) However, each thread still has its own registers and its own stack, but other threads can read and write the stack memory
A thread is a particular execution path of a process; when one thread modifies a process resource, the change is immediately visible to sibling threads
[Inter-Process communications] (http://en.wikipedia.org/wiki/Inter-process_communication)
- Sharing information; for example, web servers use IPC to share web documents and media with users through a web browser.
- Distributing labor across systems; for example, Wikipedia uses multiple servers that communicate with one another using IPC to process user requests.[2]
- Privilege separation; for example, HMI software systems are separated into layers based on privileges to minimize the risk of attacks. These layers communicate with one another using encrypted IPC.
- Approaches: File, Signal, Socket, Message queue, Pipe, Semaphore, Shared memory.
- browser checks cache; if requested object is in cache and is fresh, skip to #9
- browser asks OS for server's IP address
- OS makes a DNS lookup and replies the IP address to the browser(host/dig)
- browser opens a TCP connection to server (this step is much more complex with HTTPS)
- browser sends the HTTP request through TCP connection
- browser receives HTTP response and may close the TCP connection, or reuse it for another request
- browser checks if the response is a redirect (3xx result status codes), authorization request (401), error (4xx and 5xx), etc.; these are handled differently from normal responses (2xx)
- if cacheable, response is stored in cache
- browser decodes response (e.g. if it's gzipped)
- browser determines what to do with response (e.g. is it a HTML page, is it an image, is it a sound clip?)
- browser renders response, or offers a download dialog for unrecognized types
- Transmission Control Protocol (TCP) is a connection oriented protocol, which means the devices should open a connection before transmitting data and should close the connection gracefully after transmitting the data.
- Transmission Control Protocol (TCP) assure reliable delivery of data to the destination.
- Transmission Control Protocol (TCP) protocol provides extensive error checking mechanisms such as flow control and acknowledgment of data.
- Sequencing of data is a feature of Transmission Control Protocol (TCP).
- Delivery of data is guaranteed if you are using Transmission Control Protocol (TCP).
- Transmission Control Protocol (TCP) is comparatively slow because of these extensive error checking mechanisms
- Multiplexing and Demultiplexing is possible in Transmission Control Protocol (TCP) using TCP port numbers.
- Retransmission of lost packets is possible in Transmission Control Protocol (TCP).
- User Datagram Protocol (UDP) is Datagram oriented protocol with no overhead for opening, maintaining, and closing a connection.
- User Datagram Protocol (UDP) is efficient for broadcast/multicast transmission.
- User Datagram protocol (UDP) has only the basic error checking mechanism using checksums.
- There is no sequencing of data in User Datagram protocol (UDP) .
- The delivery of data cannot be guaranteed in User Datagram protocol (UDP) .
- User Datagram protocol (UDP) is faster, simpler and more efficient than TCP. However, User Datagram protocol (UDP) it is less robust then TCP
- Multiplexing and Demultiplexing is possible in User Datagram Protcol (UDP) using UDP port numbers.
There is no retransmission of lost packets in User Datagram Protcol (UDP).
3. VLAN
- A VLAN is a switched network that is logically segmented on an organizational basis, by functions, project teams, or applications rather than on a physical or geographical basis. For example, all workstations and servers used by a particular workgroup team can be connected to the same VLAN, regardless of their physical connections to the network or the fact that they might be intermingled with other teams. Reconfiguration of the network can be done through software rather than by physically unplugging and moving devices or wires.
- A VLAN can be thought of as a broadcast domain that exists within a defined set of switches. A VLAN consists of a number of end systems, either hosts or network equipment (such as bridges and routers), connected by a single bridging domain. The bridging domain is supported on various pieces of network equipment; for example, LAN switches that operate bridging protocols between them with a separate bridge group for each VLAN.
- VLANs are created to provide the segmentation services traditionally provided by routers in LAN configurations. VLANs address scalability, security, and network management. Routers in VLAN topologies provide broadcast filtering, security, address summarization, and traffic flow management. None of the switches within the defined group will bridge any frames, not even broadcast frames, between two VLANs.
- An Interior Gateway Protocol (IGP) is a type of protocol used for exchanging routing information between gateways (commonly routers) within an Autonomous System (for example, a system of corporate local area networks). This routing information can then be used to route network-level protocols like IP.
- Interior gateway protocols can be divided into two categories: distance-vector routing protocols and link-state routing protocols. Specific examples of IGP protocols include Open Shortest Path First (OSPF), Routing Information Protocol (RIP) and Intermediate System to Intermediate System (IS-IS).
HostA <---------> Router <----------> HostB
192.168.3.1 192.168.3.2 192.168.4.1 192.168.4.2
HostA: 192.168.3.1
Default Gateway A: 192.168.3.2
Default Gateway B: 192.168.4.1
HostB: 192.168.4.2
- Application need to send the packets to HostB, first choose the UDP or the TCP, here the UDP selected, not nessary to setup a session, the applicateion can start sending the data.
- UDP add the UDP header and passes the PDU to the IP(Layer 3) with an instruction to send the PDU to 192.168.4.2, IP encapsulates the PDU in the Layer 3 packet, setting hte source IP address(SRC IP) of the packet to the 192.169.3.1, while the destination IP addrss is set to 192.168.4.2
- Then the Layer3 find the destination IP(192.168.4.0/24) is on the different segments with source IP(192.168.3.0/24), the host sends any packets that is not destined for the local IP network to the default gateway. The default gateway is the address of the local router, which must be configured on hosts(PCs, servers,and so on). IP encapsulates the PDU in a Layer 3 packet and passes it into Layer2 with instructions to forward it to the default gateway.
- To deliver the packet, the host needs the Layer 2 informaiton of the next-hop device. The ARP table in the host does not have any entry and must resolve the Layer 2 address(MAC address) of the default gateway.
- HostA send the ARP request DST MAC: Brodcast, source MAC: hostA to the defaultgateway, then the router receive it, the router add the HostA ip address and MAC adress in it's ARP table.
- And then the router processes the ARP request and sends the ARP reply with its own informaiton.
- Now the host receives an ARP(Link Layer) reply to the ARP request and enters the inormation in its local ARP table.
- HostA could send out the pending frame now, USE the HostA IP address and MAC address as the source, but the DES IP address is the HOST B, the DES MAC address is DEFAULT GATEWAY !!!!!
- When the frame is received by the router, the router recognizes its MAC address and processes the frame. At Layer 3, the router sees that the DES IP is not its IP address. A host Layer 3 device would discard the frame. but the router will pass all packets that are for unkown DES to the routing process.
- Router look up the DES IP in the routing table, here, the DES segment is direcly connected, therefore, the routing process can pass the packet directly to Layer2 for the appropriate interface.
- Routing table has entries: destination, next hop, interface
- Then use the ARP request to get the MAC address of Host B, which is the same as Step 4, Host B will update its ARP table and send the ARP reply to the router.
- The router populates its local ARP table and starts the packet-forwarding process
- Then the frame is forwarded to the destination. The router change the MAC address, but keep the IP address, so here SRC IP: HOST A IP, DES IP: HOSTB IP, SRC MAC ADDR: Router MAC , DES MAC: HOSTB MAC
Router changes SRC and DES MAC address, but the SRC and DES IP address will not change !!!! The switch does not change the frame in any way, it just forwards the frame out on the proper port according to the MAC address table.
All frames pass through the switch unchanges, when the MAC address table is built, all unicast frames are sent directly to a destination host based on the destination MAC address and data stored in MAC address table.
ARP table used to map an IP address to a MAC address.
To show arp entries, just type show arp and you will see results like this:
Protocol Address Age (min) Hardware Addr Type Interface
Internet 10.4.2.4 10 0000.0c07.ac14 ARPA FastEthernet0/0
Internet 10.3.3.3 10 0000.0c07.ac14 ARPA FastEthernet0/0
Internet 10.3.2.7 10 0000.0c07.ac14 ARPA FastEthernet0/0
Internet 10.4.2.1 10 0007.b400.1401 ARPA FastEthernet0/0
Internet 10.3.3.7 10 0000.0c07.ac14 ARPA FastEthernet0/0
MAC table
switch(config)# sho mac address-table
Note: MAC table entries displayed are getting read from software.
Use the 'hardware-age' keyword to get information related to 'Age'
Legend:
* - primary entry, G - Gateway MAC, (R) - Routed MAC, O - Overlay MAC
age - seconds since last seen,+ - primary entry using vPC Peer-Link, E -
EVPN entry
(T) - True, (F) - False , ~~~ - use 'hardware-age' keyword to retrieve
age info
VLAN/BD MAC Address Type age Secure NTFY Ports/SWID.SSID.LID
---------+-----------------+--------+---------+------+----+------------------
G - 0018.bad8.0815 static - F F sup-eth1(R)
#####The ping command is a very common method for troubleshooting the accessibility of devices. It uses a series of Internet Control Message Protocol (ICMP) Echo messages to determine:
- Whether a remote host is active or inactive.
- The round-trip delay in communicating with the host.
- Packet loss.
- Ping operates by sending Internet Control Message Protocol (ICMP) echo request packets to the target host and waiting for an ICMP response. In the process it measures the time from transmission to reception (round-trip time)[1] and records any packet loss.
- ICMP messages are typically used for diagnostic or control purposes or generated in response to errors in IP operations
- Ping message format: ICMP 32-byte packet: IP Header, ICMP Header, ICMP payload
Error 1: Since no routing protocols are running on Router1, it does not know where to send its packet and we get an "unroutable" message. Now let us add a static route to Router1:
Router1#ping 34.0.0.4
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 34.0.0.4, timeout is 2 seconds:
Jan 20 16:00:25.603: IP: s=12.0.0.1 (local), d=34.0.0.4, len 100, unroutable.
Jan 20 16:00:27.599: IP: s=12.0.0.1 (local), d=34.0.0.4, len 100, unroutable.
Jan 20 16:00:29.599: IP: s=12.0.0.1 (local), d=34.0.0.4, len 100, unroutable.
Jan 20 16:00:31.599: IP: s=12.0.0.1 (local), d=34.0.0.4, len 100, unroutable.
Jan 20 16:00:33.599: IP: s=12.0.0.1 (local), d=34.0.0.4, len 100, unroutable.
Success rate is 0 percent (0/5)
Error 2: Check the internal router one by one to see if the packet has arrival to the destination or not. Router1 is correctly sending its packets to Router2, but Router2 doesn't know how to access address 34.0.0.4. Router2 sends back an "unreachable ICMP" message to Router1.
Router2#debug ip packet detail
IP packet debugging is on (detailed)
Router2#
Jan 20 16:10:41.907: IP: s=12.0.0.1 (Serial1), d=34.0.0.4, len 100, unroutable
Jan 20 16:10:41.911: ICMP type=8, code=0
Jan 20 16:10:41.915: IP: s=12.0.0.2 (local), d=12.0.0.1 (Serial1), len 56, sending
Jan 20 16:10:41.919: ICMP type=3, code=1
Jan 20 16:10:41.947: IP: s=12.0.0.1 (Serial1), d=34.0.0.4, len 100, unroutable
Jan 20 16:10:41.951: ICMP type=8, code=0
Jan 20 16:10:43.943: IP: s=12.0.0.1 (Serial1), d=34.0.0.4, len 100, unroutable
Jan 20 16:10:43.947: ICMP type=8, code=0
Jan 20 16:10:43.951: IP: s=12.0.0.2 (local), d=12.0.0.1 (Serial1), len 56, sending
Jan 20 16:10:43.955: ICMP type=3, code=1
Jan 20 16:10:43.983: IP: s=12.0.0.1 (Serial1), d=34.0.0.4, len 100, unroutable
Jan 20 16:10:43.987: ICMP type=8, code=0
Jan 20 16:10:45.979: IP: s=12.0.0.1 (Serial1), d=34.0.0.4, len 100, unroutable
Jan 20 16:10:45.983: ICMP type=8, code=0
Jan 20 16:10:45.987: IP: s=12.0.0.2 (local), d=12.0.0.1 (Serial1), len 56, sending
Jan 20 16:10:45.991: ICMP type=3, code=1
Router4#show arp
Protocol Address Age (min) Hardware Addr Type Interface
Internet 100.0.0.4 - 0000.0c5d.7a0d ARPA Ethernet0
Internet 100.0.0.1 10 0060.5cf4.a955 ARPA Ethernet0
Router1#ping 12.0.0.2
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 12.0.0.2, timeout is 2 seconds:
.....
Success rate is 0 percent (0/5)
Reference:
- Ping command Cisco
- Troubleshoot a ping failure (this one is better than below)
- How to troubleshoot a ping failure
- Large broadcast domain
- Management and support difficulties
- Possible security vulnerabilities
- Failure domains
- VLAN = broadcast domain
- VLAN = logical network (subnet)
- A 12-bit VLAN ID field within the 802.1q tag is used to specify the VLAN to which the frame belongs
- IP address used in the switch must be in the management VLAN, which by default is VLAN 1
- Combines the functionality of a switch and a router into one device
- To enable a Layer-3 switch to perform routing functions, VLAN interfaces on the switch need to be properly configured. You must use the IP addresses that match the subnet that the VLAN is associated with one the network.
-
301, 302 是 HTTP的response code
-
A 301 redirect says that the URL requested (the short URL) has “permanently” moved to the long address. Since it’s a permanent redirect, search engines finding links to the short URLs will credit all those links to the long URL (see the SEO: Redirects & Moving Sites section of the Search Engine Land members library for more about redirection).
-
In contrast, a 302 redirect is a “temporary” one. If that’s issued, search engines assume that the short URL is the “real” URL and just temporarily being pointed elsewhere. That means link credit does not get passed on to the long URL.
-
用301的好处是,它可以永久性的绑定在long url上面,提高credict,但是坏处是:浏览器碰到301, 它会意识到这个是permanently, 所以会cache,然后直接访问,则不会往url shortern发送requrest,而是直接获取地址,这样就无法track到原来地址用的多少次的信息。所以 解决方法是prevent cache
-
For example:
-
在'Inspect Element'里面,如果输入shorten URL:可以发现 'no-cache, no-store, max-age=0, must-revalidate'
Remote Address:[2607:f8b0:4007:80a::200e]:80
Request URL:http://goo.gl/mD14Uu
Request Method:GET
Status Code:301 Moved Permanently
Response Headers
view source
Alternate-Protocol:80:quic,p=1
Cache-Control:no-cache, no-store, max-age=0, must-revalidate
Content-Encoding:gzip
- SSL stands for Secure Sockets Layer.
- It provides a secure connection between internet browsers and websites, allowing you to transmit private data online. Sites secured with SSL display a padlock in the browsers URL and possibly a green address bar if secured by an EV Certificate
- GET requests a representation of the specified resource. Note that GET should not be used for operations that cause side-effects, such as using it for taking actions in web applications. One reason for this is that GET may be used arbitrarily by robots or crawlers, which should not need to consider the side effects that a request should cause.
- POST submits data to be processed (e.g., from an HTML form) to the identified resource. The data is included in the body of the request. This may result in the creation of a new resource or the updates of existing resources or both.
-
- Authors of services which use the HTTP protocol SHOULD NOT use GET based forms for the submission of sensitive data, because this will cause this data to be encoded in the Request-URI. Many existing servers, proxies, and user agents will log the request URI in some place where it might be visible to third parties. Servers can use POST-based form submission instead
-
2
-
It's not a matter of security. The HTTP protocol defines GET-type requests as being idempotent, while POSTs may have side effects. In plain English, that means that GET is used for viewing something, without changing it, while POST is used for changing something. For example, a search page should use GET, while a form that changes your password should use POST.
-
Also, note that PHP confuses the concepts a bit. A POST request gets input from the query string and through the request body. A GET request just gets input from the query string. So a POST request is a superset of a GET request; you can use $_GET in a POST request, and it may even make sense to have parameters with the same name in $_POST and $_GET that mean different things.
-
For example, let's say you have a form for editing an article. The article-id may be in the query string (and, so, available through $_GET['id']), but let's say that you want to change the article-id. The new id may then be present in the request body ($_POST['id']). OK, perhaps that's not the best example, but I hope it illustrates the difference between the two.
-
-
-
- Some of the methods (for example, HEAD, GET, OPTIONS and TRACE) are, by convention, defined as safe, which means they are intended only for information retrieval and should not change the state of the server. In other words, they should not have side effects, beyond relatively harmless effects such as logging, caching, the serving of banner advertisements or incrementing a web counter. Making arbitrary GET requests without regard to the context of the application's state should therefore be considered safe. However, this is not mandated by the standard, and it is explicitly acknowledged that it cannot be guaranteed.
- By contrast, methods such as POST, PUT, DELETE and PATCH are intended for actions that may cause side effects either on the server, or external side effects such as financial transactions or transmission of email. Such methods are therefore not usually used by conforming web robots or web crawlers; some that do not conform tend to make requests without regard to context or consequences.
-

- the SSL connection is between the TCP layer and the HTTP layer. The client and server first establish a secure encrypted TCP connection (via the SSL/TLS protocol) and then the client will send the HTTP request (either GET or POST) over that encrypted TCP connection.
- Expires策略:Web服务器响应消息头字段,在响应http请求时告诉浏览器在过期时间前浏览器可以直接从浏览器缓存取数据
- HTTP defines three basic mechanisms for controlling caches: freshness, validation, and invalidation
- allows a response to be used without re-checking it on the origin server, and can be controlled by both the server and the client. For example, the Expires response header gives a date when the document becomes stale, and the Cache-Control: max-age directive tells the cache how many seconds the response is fresh for.
- can be used to check whether a cached response is still good after it becomes stale. For example, if the response has a Last-Modified header, a cache can make a conditional request using the If-Modified-Since header to see if it has changed. The ETag (entity tag) mechanism also allows for both strong and weak validation.
- is usually a side effect of another request that passes through the cache. For example, if a URL associated with a cached response subsequently gets a POST, PUT or DELETE request, the cached response will be invalidated.
- How cache works? (Good Blog!)
- What is the difference between POST and GET
- w3school HTTP POST and GET
- Are https URLs encrypted?
-
Instead of HyperText Transfer Protocol (HTTP), this website uses HyperText Transfer Protocol Secure (HTTPS).
-
Using HTTPS, the computers agree on a "code" between them, and then they scramble the messages using that "code" so that no one in between can read them. This keeps your information safe from hackers.
-
They use the "code" on a Secure Sockets Layer (SSL), sometimes called Transport Layer Security (TLS) to send the information back and forth
- key word * ISP query recursive resolver * what is recurisive resolver * Recursive resolver first checking the root server, each one knows DNS info about Top Level Domains(TLD) such as .com * The TLD DNS name server stores the address informaiton for second level domains * Recursive resolver send the query to the domain name server. * The DNS knows the IP address for the full domain, return back to Recursive resolver. * Then return back to browser