These are some of the main principles underlying the course structure.
The product is you, NOT what you build.
-
The software product you build is a side effect only. You are the product of this course. This means,
We may not take the most efficient route to building the software product. We take the route that allows you to learn the most.
Building a software product that is unique, creative, and shiny is not our priority (although we try to do a bit of that too). Learning to take pride in, and discovering the joy of, high quality software engineering work is our priority.
Following from that, we evaluate you on not just how much you've done, but also, how well you've done those things. Here are some of the aspects in which we focus on:
We appreciate ...
But we value more ...
Ability to deal with low-level details
Ability to abstract over details, generalize, see the big picture
A drive to learn latest and greatest technologies
Ability to make the best of given tools
Ability to find problems that interest you and solve them
Ability to solve the given problem to the best of your ability
Ability to burn the midnight oil to meet a deadline
Ability to schedule work so that the need for 'last minute heroics' is minimal
Preference to do things you like or things you are good at
Ability to buckle down and deliver on important things that you don't necessarily like or are good at
Ability to deliver desired end results
Ability to deliver in a way that shows how well you delivered (i.e. visibility of your work)
We learn together, NOT compete against each other.
You are not in a competition. Our grading is not forced on a bell curve.
Learn from each other. That is why we open-source your submissions.
Teach each other, even those in other teams. Those who do it well can become tutors next time.
Continuously engage, NOT last minute heroics.
We want to train you to do software engineering in a steady and repeatable manner that does not require 'last minute heroics'.
In this course, last minute heroics will not earn you a good project grade, and last minute mugging will not earn you a good exam grade.
Where you reach at the end matters, NOT what you knew at the beginning.
When you start the course, some others in the class may appear to know a lot more than you. Don't let that worry you. The final grade depends on what you know at the end, not what you knew to begin with. All marks allocated to intermediate deliverables are within the reach of everyone in the class irrespective of their prior knowledge.
The software product you build is a side effect only. You are the product of this course. This means,
We may not take the most efficient route to building the software product. We take the route that allows you to learn the most.
Building a software product that is unique, creative, and shiny is not our priority (although we try to do a bit of that too). Learning to take pride in, and discovering the joy of, high quality software engineering work is our priority.
Following from that, we evaluate you on not just how much you've done, but also, how well you've done those things. Here are some of the aspects in which we focus on:
We appreciate ...
But we value more ...
Ability to deal with low-level details
Ability to abstract over details, generalize, see the big picture
A drive to learn latest and greatest technologies
Ability to make the best of given tools
Ability to find problems that interest you and solve them
Ability to solve the given problem to the best of your ability
Ability to burn the midnight oil to meet a deadline
Ability to schedule work so that the need for 'last minute heroics' is minimal
Preference to do things you like or things you are good at
Ability to buckle down and deliver on important things that you don't necessarily like or are good at
Ability to deliver desired end results
Ability to deliver in a way that shows how well you delivered (i.e. visibility of your work)
We learn together, NOT compete against each other.
You are not in a competition. Our grading is not forced on a bell curve.
Learn from each other. That is why we open-source your submissions.
Teach each other, even those in other teams. Those who do it well can become tutors next time.
Continuously engage, NOT last minute heroics.
We want to train you to do software engineering in a steady and repeatable manner that does not require 'last minute heroics'.
In this course, last minute heroics will not earn you a good project grade, and last minute mugging will not earn you a good exam grade.
Where you reach at the end matters, NOT what you knew at the beginning.
When you start the course, some others in the class may appear to know a lot more than you. Don't let that worry you. The final grade depends on what you know at the end, not what you knew to begin with. All marks allocated to intermediate deliverables are within the reach of everyone in the class irrespective of their prior knowledge.
COMMON MISTAKE:Not following the convention for Git commit message subject.
-Caution: This is very hard to rectify later, after the PR containing the commits have been merged. Reason: While Git allows editing past commits, doing so changes their timestamp, which affects your weekly code contribution stats (which are factored into evaluating the consistency of your coding work over the project duration).
COMMON MISTAKE:Forgetting to do each PR from a separate branch (i.e., send PR from the master branch) of your fork. This error means your PR will not be considered as following the forking workflow correctly.
COMMON MISTAKE:Not giving enough PR review comments. Remember to do proper PR reviews throughout the tP, at least for non-trivial changes, as the quality and quantity of PR review comments you have given to peers affect your tP marks (under the project management aspect).
+Caution: This is very hard to rectify later, after the PR containing the commits have been merged. Reason: While Git allows editing past commits, doing so changes their timestamp, which affects your weekly code contribution stats (which are factored into evaluating the consistency of your coding work over the project duration).
COMMON MISTAKE:Forgetting to do each PR from a separate branch (i.e., send PR from the master branch) of your fork. This error means your PR will not be considered as following the forking workflow correctly.
COMMON MISTAKE:Not giving enough PR review comments. Remember to do proper PR reviews throughout the tP, at least for non-trivial changes, as the quality and quantity of PR review comments you have given to peers affect your tP marks (under the project management aspect).
A large portion of this book is based on learning materials created by the following Software Engineering Instructors for their students (in alphabetical order):
A large portion of this book is based on learning materials created by the following Software Engineering Instructors for their students (in alphabetical order):
Rebekah Low: For programming the initial version of this book in MarkBind format.
Design → Architecture → Styles →
-
Client-server architectural style
What
Can identify the client-server architectural style
The client-server style has at least one component playing the role of a server and at least one client component accessing the services of the server. This is an architectural style used often in distributed applications.
The online game and the web application below use the client-server style.
+
Client-server architectural style
What
Can identify the client-server architectural style
The client-server style has at least one component playing the role of a server and at least one client component accessing the services of the server. This is an architectural style used often in distributed applications.
The online game and the web application below use the client-server style.
Can identify the client-server architectural style
The client-server style has at least one component playing the role of a server and at least one client component accessing the services of the server. This is an architectural style used often in distributed applications.
The online game and the web application below use the client-server style.
+
What
The client-server style has at least one component playing the role of a server and at least one client component accessing the services of the server. This is an architectural style used often in distributed applications.
The online game and the web application below use the client-server style.
Design → Architecture → Styles →
-
Event-driven architectural style
What
Can identify event-driven architectural style
Event-driven style controls the flow of the application by detecting from event emitters and communicating those events to interested event consumers. This architectural style is often used in GUIs.
When the ‘button clicked’ event occurs in a GUI, that event can be transmitted to components that are interested in reacting to that event. Similarly, events detected at a printer port can be transmitted to components related to operating the printer. The same event can be sent to multiple consumers too.
+
Event-driven architectural style
What
Can identify event-driven architectural style
Event-driven style controls the flow of the application by detecting from event emitters and communicating those events to interested event consumers. This architectural style is often used in GUIs.
When the ‘button clicked’ event occurs in a GUI, that event can be transmitted to components that are interested in reacting to that event. Similarly, events detected at a printer port can be transmitted to components related to operating the printer. The same event can be sent to multiple consumers too.
Event-driven style controls the flow of the application by detecting from event emitters and communicating those events to interested event consumers. This architectural style is often used in GUIs.
When the ‘button clicked’ event occurs in a GUI, that event can be transmitted to components that are interested in reacting to that event. Similarly, events detected at a printer port can be transmitted to components related to operating the printer. The same event can be sent to multiple consumers too.
+
What
Event-driven style controls the flow of the application by detecting from event emitters and communicating those events to interested event consumers. This architectural style is often used in GUIs.
When the ‘button clicked’ event occurs in a GUI, that event can be transmitted to components that are interested in reacting to that event. Similarly, events detected at a printer port can be transmitted to components related to operating the printer. The same event can be sent to multiple consumers too.
Design → Architecture →
-
Architectural styles
Introduction
What
Can explain architectural styles
Software architectures follow various high-level styles (aka architectural patterns), just like how building architectures follow various architecture styles.
In the n-tier style, higher layers make use of services provided by lower layers. Lower layers are independent of higher layers. Other names: multi-layered, layered.
Operating systems and network communication software often use n-tier style.
Client-server architectural style
What
Can identify the client-server architectural style
The client-server style has at least one component playing the role of a server and at least one client component accessing the services of the server. This is an architectural style used often in distributed applications.
The online game and the web application below use the client-server style.
Transaction processing architectural style
What
Can identify transaction processing architectural style
The transaction processing style divides the workload of the system down to a number of transactions which are then given to a dispatcher that controls the execution of each transaction. Task queuing, ordering, undo etc. are handled by the dispatcher.
In this example from a banking system, transactions are generated by the terminals used by , which are then sent to a central dispatching unit, which in turn dispatches the transactions to various other units to execute.
Service-oriented architectural style
What
Can identify service-oriented architectural style
The service-oriented architecture (SOA) style builds applications by combining functionalities packaged as programmatically accessible services. SOA aims to achieve interoperability between distributed services, which may not even be implemented using the same programming language. A common way to implement SOA is through the use of XML web services where the web is used as the medium for the services to interact, and XML is used as the language of communication between service providers and service users.
Suppose that Amazon.com provides a web service for customers to browse and buy merchandise, while HSBC provides a web service for merchants to charge HSBC credit cards. Using these web services, an ‘eBookShop’ web application can be developed that allows HSBC customers to buy merchandise from Amazon and pay for them using HSBC credit cards. Because both Amazon and HSBC services follow the SOA architecture, their web services can be reused by the web application, even if all three systems use different programming platforms.
Event-driven style controls the flow of the application by detecting from event emitters and communicating those events to interested event consumers. This architectural style is often used in GUIs.
When the ‘button clicked’ event occurs in a GUI, that event can be transmitted to components that are interested in reacting to that event. Similarly, events detected at a printer port can be transmitted to components related to operating the printer. The same event can be sent to multiple consumers too.
More
More styles
Can name several other architecture styles
Other well-known architectural styles include the pipes-and-filters architecture, the broker architecture, the peer-to-peer architecture, and the message-oriented architecture.
Resources:
Pipes and Filters pattern -- an article from Microsoft about the pipes and filters architectural style
Broker pattern -- Wikipedia article on the broker architectural style
Most applications use a mix of these architectural styles.
An application can use a client-server architecture where the server component comprises several layers, i.e. it uses the n-tier architecture.
Exercises:
Comment on how to use architecture styles in Minesweeper.
+
Architectural styles
Introduction
What
Can explain architectural styles
Software architectures follow various high-level styles (aka architectural patterns), just like how building architectures follow various architecture styles.
In the n-tier style, higher layers make use of services provided by lower layers. Lower layers are independent of higher layers. Other names: multi-layered, layered.
Operating systems and network communication software often use n-tier style.
Client-server architectural style
What
Can identify the client-server architectural style
The client-server style has at least one component playing the role of a server and at least one client component accessing the services of the server. This is an architectural style used often in distributed applications.
The online game and the web application below use the client-server style.
Transaction processing architectural style
What
Can identify transaction processing architectural style
The transaction processing style divides the workload of the system down to a number of transactions which are then given to a dispatcher that controls the execution of each transaction. Task queuing, ordering, undo etc. are handled by the dispatcher.
In this example from a banking system, transactions are generated by the terminals used by , which are then sent to a central dispatching unit, which in turn dispatches the transactions to various other units to execute.
Service-oriented architectural style
What
Can identify service-oriented architectural style
The service-oriented architecture (SOA) style builds applications by combining functionalities packaged as programmatically accessible services. SOA aims to achieve interoperability between distributed services, which may not even be implemented using the same programming language. A common way to implement SOA is through the use of XML web services where the web is used as the medium for the services to interact, and XML is used as the language of communication between service providers and service users.
Suppose that Amazon.com provides a web service for customers to browse and buy merchandise, while HSBC provides a web service for merchants to charge HSBC credit cards. Using these web services, an ‘eBookShop’ web application can be developed that allows HSBC customers to buy merchandise from Amazon and pay for them using HSBC credit cards. Because both Amazon and HSBC services follow the SOA architecture, their web services can be reused by the web application, even if all three systems use different programming platforms.
Event-driven style controls the flow of the application by detecting from event emitters and communicating those events to interested event consumers. This architectural style is often used in GUIs.
When the ‘button clicked’ event occurs in a GUI, that event can be transmitted to components that are interested in reacting to that event. Similarly, events detected at a printer port can be transmitted to components related to operating the printer. The same event can be sent to multiple consumers too.
More
More styles
Can name several other architecture styles
Other well-known architectural styles include the pipes-and-filters architecture, the broker architecture, the peer-to-peer architecture, and the message-oriented architecture.
Resources:
Pipes and Filters pattern -- an article from Microsoft about the pipes and filters architectural style
Broker pattern -- Wikipedia article on the broker architectural style
Most applications use a mix of these architectural styles.
An application can use a client-server architecture where the server component comprises several layers, i.e. it uses the n-tier architecture.
Exercises:
Comment on how to use architecture styles in Minesweeper.
Design → Architecture → Styles →
-
Introduction
What
Can explain architectural styles
Software architectures follow various high-level styles (aka architectural patterns), just like how building architectures follow various architecture styles.
Software architectures follow various high-level styles (aka architectural patterns), just like how building architectures follow various architecture styles.
Software architectures follow various high-level styles (aka architectural patterns), just like how building architectures follow various architecture styles.
Software architectures follow various high-level styles (aka architectural patterns), just like how building architectures follow various architecture styles.
Other well-known architectural styles include the pipes-and-filters architecture, the broker architecture, the peer-to-peer architecture, and the message-oriented architecture.
Resources:
Pipes and Filters pattern -- an article from Microsoft about the pipes and filters architectural style
Broker pattern -- Wikipedia article on the broker architectural style
Most applications use a mix of these architectural styles.
An application can use a client-server architecture where the server component comprises several layers, i.e. it uses the n-tier architecture.
Exercises:
Comment on how to use architecture styles in Minesweeper.
+
More
More styles
Can name several other architecture styles
Other well-known architectural styles include the pipes-and-filters architecture, the broker architecture, the peer-to-peer architecture, and the message-oriented architecture.
Resources:
Pipes and Filters pattern -- an article from Microsoft about the pipes and filters architectural style
Broker pattern -- Wikipedia article on the broker architectural style
Most applications use a mix of these architectural styles.
An application can use a client-server architecture where the server component comprises several layers, i.e. it uses the n-tier architecture.
Exercises:
Comment on how to use architecture styles in Minesweeper.
Can name several other architecture styles
Design → Architecture → Styles →
-
More styles
Other well-known architectural styles include the pipes-and-filters architecture, the broker architecture, the peer-to-peer architecture, and the message-oriented architecture.
Resources:
Pipes and Filters pattern -- an article from Microsoft about the pipes and filters architectural style
Broker pattern -- Wikipedia article on the broker architectural style
Other well-known architectural styles include the pipes-and-filters architecture, the broker architecture, the peer-to-peer architecture, and the message-oriented architecture.
Resources:
Pipes and Filters pattern -- an article from Microsoft about the pipes and filters architectural style
Broker pattern -- Wikipedia article on the broker architectural style
Most applications use a mix of these architectural styles.
An application can use a client-server architecture where the server component comprises several layers, i.e. it uses the n-tier architecture.
Exercises:
Comment on how to use architecture styles in Minesweeper.
+
Using styles
Most applications use a mix of these architectural styles.
An application can use a client-server architecture where the server component comprises several layers, i.e. it uses the n-tier architecture.
Exercises:
Comment on how to use architecture styles in Minesweeper.
Design → Architecture → Styles →
-
N-tier architectural style
What
Can identify n-tier architectural style
In the n-tier style, higher layers make use of services provided by lower layers. Lower layers are independent of higher layers. Other names: multi-layered, layered.
Operating systems and network communication software often use n-tier style.
+
N-tier architectural style
What
Can identify n-tier architectural style
In the n-tier style, higher layers make use of services provided by lower layers. Lower layers are independent of higher layers. Other names: multi-layered, layered.
Operating systems and network communication software often use n-tier style.
Can identify n-tier architectural style
Design → Architecture → Styles → n-Tier Style →
-
What
In the n-tier style, higher layers make use of services provided by lower layers. Lower layers are independent of higher layers. Other names: multi-layered, layered.
Operating systems and network communication software often use n-tier style.
+
What
In the n-tier style, higher layers make use of services provided by lower layers. Lower layers are independent of higher layers. Other names: multi-layered, layered.
Operating systems and network communication software often use n-tier style.
Design → Architecture → Styles →
-
Service-oriented architectural style
What
Can identify service-oriented architectural style
The service-oriented architecture (SOA) style builds applications by combining functionalities packaged as programmatically accessible services. SOA aims to achieve interoperability between distributed services, which may not even be implemented using the same programming language. A common way to implement SOA is through the use of XML web services where the web is used as the medium for the services to interact, and XML is used as the language of communication between service providers and service users.
Suppose that Amazon.com provides a web service for customers to browse and buy merchandise, while HSBC provides a web service for merchants to charge HSBC credit cards. Using these web services, an ‘eBookShop’ web application can be developed that allows HSBC customers to buy merchandise from Amazon and pay for them using HSBC credit cards. Because both Amazon and HSBC services follow the SOA architecture, their web services can be reused by the web application, even if all three systems use different programming platforms.
The service-oriented architecture (SOA) style builds applications by combining functionalities packaged as programmatically accessible services. SOA aims to achieve interoperability between distributed services, which may not even be implemented using the same programming language. A common way to implement SOA is through the use of XML web services where the web is used as the medium for the services to interact, and XML is used as the language of communication between service providers and service users.
Suppose that Amazon.com provides a web service for customers to browse and buy merchandise, while HSBC provides a web service for merchants to charge HSBC credit cards. Using these web services, an ‘eBookShop’ web application can be developed that allows HSBC customers to buy merchandise from Amazon and pay for them using HSBC credit cards. Because both Amazon and HSBC services follow the SOA architecture, their web services can be reused by the web application, even if all three systems use different programming platforms.
The service-oriented architecture (SOA) style builds applications by combining functionalities packaged as programmatically accessible services. SOA aims to achieve interoperability between distributed services, which may not even be implemented using the same programming language. A common way to implement SOA is through the use of XML web services where the web is used as the medium for the services to interact, and XML is used as the language of communication between service providers and service users.
Suppose that Amazon.com provides a web service for customers to browse and buy merchandise, while HSBC provides a web service for merchants to charge HSBC credit cards. Using these web services, an ‘eBookShop’ web application can be developed that allows HSBC customers to buy merchandise from Amazon and pay for them using HSBC credit cards. Because both Amazon and HSBC services follow the SOA architecture, their web services can be reused by the web application, even if all three systems use different programming platforms.
The service-oriented architecture (SOA) style builds applications by combining functionalities packaged as programmatically accessible services. SOA aims to achieve interoperability between distributed services, which may not even be implemented using the same programming language. A common way to implement SOA is through the use of XML web services where the web is used as the medium for the services to interact, and XML is used as the language of communication between service providers and service users.
Suppose that Amazon.com provides a web service for customers to browse and buy merchandise, while HSBC provides a web service for merchants to charge HSBC credit cards. Using these web services, an ‘eBookShop’ web application can be developed that allows HSBC customers to buy merchandise from Amazon and pay for them using HSBC credit cards. Because both Amazon and HSBC services follow the SOA architecture, their web services can be reused by the web application, even if all three systems use different programming platforms.
Can identify transaction processing architectural style
The transaction processing style divides the workload of the system down to a number of transactions which are then given to a dispatcher that controls the execution of each transaction. Task queuing, ordering, undo etc. are handled by the dispatcher.
In this example from a banking system, transactions are generated by the terminals used by , which are then sent to a central dispatching unit, which in turn dispatches the transactions to various other units to execute.
+
Transaction processing architectural style
What
Can identify transaction processing architectural style
The transaction processing style divides the workload of the system down to a number of transactions which are then given to a dispatcher that controls the execution of each transaction. Task queuing, ordering, undo etc. are handled by the dispatcher.
In this example from a banking system, transactions are generated by the terminals used by , which are then sent to a central dispatching unit, which in turn dispatches the transactions to various other units to execute.
Can identify transaction processing architectural style
The transaction processing style divides the workload of the system down to a number of transactions which are then given to a dispatcher that controls the execution of each transaction. Task queuing, ordering, undo etc. are handled by the dispatcher.
In this example from a banking system, transactions are generated by the terminals used by , which are then sent to a central dispatching unit, which in turn dispatches the transactions to various other units to execute.
+
What
The transaction processing style divides the workload of the system down to a number of transactions which are then given to a dispatcher that controls the execution of each transaction. Task queuing, ordering, undo etc. are handled by the dispatcher.
In this example from a banking system, transactions are generated by the terminals used by , which are then sent to a central dispatching unit, which in turn dispatches the transactions to various other units to execute.
Can draw an architecture diagram
Design → Architecture → Architecture Diagrams →
-
Drawing
While architecture diagrams have no standard notation, try to follow these basic guidelines when drawing them.
Minimize the variety of symbols. If the symbols you choose do not have widely-understood meanings e.g. A drum symbol is widely-understood as representing a database, explain their meaning.
Avoid the indiscriminate use of double-headed arrows to show interactions between components.
Consider the two architecture diagrams of the same software given below. Because Diagram 2 uses double-headed arrows, the important fact that GUI has a bidirectional dependency with the Logic component is no longer captured.
+
Drawing
While architecture diagrams have no standard notation, try to follow these basic guidelines when drawing them.
Minimize the variety of symbols. If the symbols you choose do not have widely-understood meanings e.g. A drum symbol is widely-understood as representing a database, explain their meaning.
Avoid the indiscriminate use of double-headed arrows to show interactions between components.
Consider the two architecture diagrams of the same software given below. Because Diagram 2 uses double-headed arrows, the important fact that GUI has a bidirectional dependency with the Logic component is no longer captured.
Design → Architecture →
-
Architecture diagrams
Reading
Can interpret an architecture diagram
Architecture diagrams are free-form diagrams. There is no universally adopted standard notation for architecture diagrams. Any symbols that reasonably describe the architecture may be used.
While architecture diagrams have no standard notation, try to follow these basic guidelines when drawing them.
Minimize the variety of symbols. If the symbols you choose do not have widely-understood meanings e.g. A drum symbol is widely-understood as representing a database, explain their meaning.
Avoid the indiscriminate use of double-headed arrows to show interactions between components.
Consider the two architecture diagrams of the same software given below. Because Diagram 2 uses double-headed arrows, the important fact that GUI has a bidirectional dependency with the Logic component is no longer captured.
+
Architecture diagrams
Reading
Can interpret an architecture diagram
Architecture diagrams are free-form diagrams. There is no universally adopted standard notation for architecture diagrams. Any symbols that reasonably describe the architecture may be used.
While architecture diagrams have no standard notation, try to follow these basic guidelines when drawing them.
Minimize the variety of symbols. If the symbols you choose do not have widely-understood meanings e.g. A drum symbol is widely-understood as representing a database, explain their meaning.
Avoid the indiscriminate use of double-headed arrows to show interactions between components.
Consider the two architecture diagrams of the same software given below. Because Diagram 2 uses double-headed arrows, the important fact that GUI has a bidirectional dependency with the Logic component is no longer captured.
Can interpret an architecture diagram
Design → Architecture → Architecture Diagrams →
-
Reading
Architecture diagrams are free-form diagrams. There is no universally adopted standard notation for architecture diagrams. Any symbols that reasonably describe the architecture may be used.
Architecture diagrams are free-form diagrams. There is no universally adopted standard notation for architecture diagrams. Any symbols that reasonably describe the architecture may be used.
The software architecture of a program or computing system is the structure or structures of the system, which comprise software elements, the externally visible properties of those elements, and the relationships among them. Architecture is concerned with the public side of interfaces; private details of elements—details having to do solely with internal implementation—are not architectural.
--- Software Architecture in Practice (2nd edition), Bass, Clements, and Kazman
The software architecture shows the overall organization of the system and can be viewed as a very high-level design. It usually consists of a set of interacting components that fit together to achieve the required functionality. It should be a simple and technically viable structure that is well-understood and agreed-upon by everyone in the development team, and it forms the basis for the implementation.
A possible architecture for a Minesweeper game:
Main components:
GUI: Graphical user interface
TextUi: Textual user interface
ATD: An automated test driver used for testing the game logic
Logic: Computation and logic of the game
Store: Storage and retrieval of game data (high scores etc.)
The architecture is typically designed by the software architect, who provides the technical vision of the system and makes high-level (i.e. architecture-level) technical decisions about the project.
Exercises:
Statements about architecture
Architecture diagrams
Reading
Can interpret an architecture diagram
Architecture diagrams are free-form diagrams. There is no universally adopted standard notation for architecture diagrams. Any symbols that reasonably describe the architecture may be used.
While architecture diagrams have no standard notation, try to follow these basic guidelines when drawing them.
Minimize the variety of symbols. If the symbols you choose do not have widely-understood meanings e.g. A drum symbol is widely-understood as representing a database, explain their meaning.
Avoid the indiscriminate use of double-headed arrows to show interactions between components.
Consider the two architecture diagrams of the same software given below. Because Diagram 2 uses double-headed arrows, the important fact that GUI has a bidirectional dependency with the Logic component is no longer captured.
Architectural styles
Introduction
What
Can explain architectural styles
Software architectures follow various high-level styles (aka architectural patterns), just like how building architectures follow various architecture styles.
In the n-tier style, higher layers make use of services provided by lower layers. Lower layers are independent of higher layers. Other names: multi-layered, layered.
Operating systems and network communication software often use n-tier style.
Client-server architectural style
What
Can identify the client-server architectural style
The client-server style has at least one component playing the role of a server and at least one client component accessing the services of the server. This is an architectural style used often in distributed applications.
The online game and the web application below use the client-server style.
Transaction processing architectural style
What
Can identify transaction processing architectural style
The transaction processing style divides the workload of the system down to a number of transactions which are then given to a dispatcher that controls the execution of each transaction. Task queuing, ordering, undo etc. are handled by the dispatcher.
In this example from a banking system, transactions are generated by the terminals used by , which are then sent to a central dispatching unit, which in turn dispatches the transactions to various other units to execute.
Service-oriented architectural style
What
Can identify service-oriented architectural style
The service-oriented architecture (SOA) style builds applications by combining functionalities packaged as programmatically accessible services. SOA aims to achieve interoperability between distributed services, which may not even be implemented using the same programming language. A common way to implement SOA is through the use of XML web services where the web is used as the medium for the services to interact, and XML is used as the language of communication between service providers and service users.
Suppose that Amazon.com provides a web service for customers to browse and buy merchandise, while HSBC provides a web service for merchants to charge HSBC credit cards. Using these web services, an ‘eBookShop’ web application can be developed that allows HSBC customers to buy merchandise from Amazon and pay for them using HSBC credit cards. Because both Amazon and HSBC services follow the SOA architecture, their web services can be reused by the web application, even if all three systems use different programming platforms.
Event-driven style controls the flow of the application by detecting from event emitters and communicating those events to interested event consumers. This architectural style is often used in GUIs.
When the ‘button clicked’ event occurs in a GUI, that event can be transmitted to components that are interested in reacting to that event. Similarly, events detected at a printer port can be transmitted to components related to operating the printer. The same event can be sent to multiple consumers too.
More
More styles
Can name several other architecture styles
Other well-known architectural styles include the pipes-and-filters architecture, the broker architecture, the peer-to-peer architecture, and the message-oriented architecture.
Resources:
Pipes and Filters pattern -- an article from Microsoft about the pipes and filters architectural style
Broker pattern -- Wikipedia article on the broker architectural style
Most applications use a mix of these architectural styles.
An application can use a client-server architecture where the server component comprises several layers, i.e. it uses the n-tier architecture.
Exercises:
Comment on how to use architecture styles in Minesweeper.
+-- Software Architecture in Practice (2nd edition), Bass, Clements, and Kazman
The software architecture shows the overall organization of the system and can be viewed as a very high-level design. It usually consists of a set of interacting components that fit together to achieve the required functionality. It should be a simple and technically viable structure that is well-understood and agreed-upon by everyone in the development team, and it forms the basis for the implementation.
A possible architecture for a Minesweeper game:
Main components:
GUI: Graphical user interface
TextUi: Textual user interface
ATD: An automated test driver used for testing the game logic
Logic: Computation and logic of the game
Store: Storage and retrieval of game data (high scores etc.)
The architecture is typically designed by the software architect, who provides the technical vision of the system and makes high-level (i.e. architecture-level) technical decisions about the project.
Exercises:
Statements about architecture
Architecture diagrams
Reading
Can interpret an architecture diagram
Architecture diagrams are free-form diagrams. There is no universally adopted standard notation for architecture diagrams. Any symbols that reasonably describe the architecture may be used.
While architecture diagrams have no standard notation, try to follow these basic guidelines when drawing them.
Minimize the variety of symbols. If the symbols you choose do not have widely-understood meanings e.g. A drum symbol is widely-understood as representing a database, explain their meaning.
Avoid the indiscriminate use of double-headed arrows to show interactions between components.
Consider the two architecture diagrams of the same software given below. Because Diagram 2 uses double-headed arrows, the important fact that GUI has a bidirectional dependency with the Logic component is no longer captured.
Architectural styles
Introduction
What
Can explain architectural styles
Software architectures follow various high-level styles (aka architectural patterns), just like how building architectures follow various architecture styles.
In the n-tier style, higher layers make use of services provided by lower layers. Lower layers are independent of higher layers. Other names: multi-layered, layered.
Operating systems and network communication software often use n-tier style.
Client-server architectural style
What
Can identify the client-server architectural style
The client-server style has at least one component playing the role of a server and at least one client component accessing the services of the server. This is an architectural style used often in distributed applications.
The online game and the web application below use the client-server style.
Transaction processing architectural style
What
Can identify transaction processing architectural style
The transaction processing style divides the workload of the system down to a number of transactions which are then given to a dispatcher that controls the execution of each transaction. Task queuing, ordering, undo etc. are handled by the dispatcher.
In this example from a banking system, transactions are generated by the terminals used by , which are then sent to a central dispatching unit, which in turn dispatches the transactions to various other units to execute.
Service-oriented architectural style
What
Can identify service-oriented architectural style
The service-oriented architecture (SOA) style builds applications by combining functionalities packaged as programmatically accessible services. SOA aims to achieve interoperability between distributed services, which may not even be implemented using the same programming language. A common way to implement SOA is through the use of XML web services where the web is used as the medium for the services to interact, and XML is used as the language of communication between service providers and service users.
Suppose that Amazon.com provides a web service for customers to browse and buy merchandise, while HSBC provides a web service for merchants to charge HSBC credit cards. Using these web services, an ‘eBookShop’ web application can be developed that allows HSBC customers to buy merchandise from Amazon and pay for them using HSBC credit cards. Because both Amazon and HSBC services follow the SOA architecture, their web services can be reused by the web application, even if all three systems use different programming platforms.
Event-driven style controls the flow of the application by detecting from event emitters and communicating those events to interested event consumers. This architectural style is often used in GUIs.
When the ‘button clicked’ event occurs in a GUI, that event can be transmitted to components that are interested in reacting to that event. Similarly, events detected at a printer port can be transmitted to components related to operating the printer. The same event can be sent to multiple consumers too.
More
More styles
Can name several other architecture styles
Other well-known architectural styles include the pipes-and-filters architecture, the broker architecture, the peer-to-peer architecture, and the message-oriented architecture.
Resources:
Pipes and Filters pattern -- an article from Microsoft about the pipes and filters architectural style
Broker pattern -- Wikipedia article on the broker architectural style
Most applications use a mix of these architectural styles.
An application can use a client-server architecture where the server component comprises several layers, i.e. it uses the n-tier architecture.
Exercises:
Comment on how to use architecture styles in Minesweeper.
Design → Architecture →
Introduction
What
Can explain Software Architecture
The software architecture of a program or computing system is the structure or structures of the system, which comprise software elements, the externally visible properties of those elements, and the relationships among them. Architecture is concerned with the public side of interfaces; private details of elements—details having to do solely with internal implementation—are not architectural.
--- Software Architecture in Practice (2nd edition), Bass, Clements, and Kazman
The software architecture shows the overall organization of the system and can be viewed as a very high-level design. It usually consists of a set of interacting components that fit together to achieve the required functionality. It should be a simple and technically viable structure that is well-understood and agreed-upon by everyone in the development team, and it forms the basis for the implementation.
A possible architecture for a Minesweeper game:
Main components:
GUI: Graphical user interface
TextUi: Textual user interface
ATD: An automated test driver used for testing the game logic
Logic: Computation and logic of the game
Store: Storage and retrieval of game data (high scores etc.)
The architecture is typically designed by the software architect, who provides the technical vision of the system and makes high-level (i.e. architecture-level) technical decisions about the project.
Exercises:
Statements about architecture
+-- Software Architecture in Practice (2nd edition), Bass, Clements, and Kazman
The software architecture shows the overall organization of the system and can be viewed as a very high-level design. It usually consists of a set of interacting components that fit together to achieve the required functionality. It should be a simple and technically viable structure that is well-understood and agreed-upon by everyone in the development team, and it forms the basis for the implementation.
A possible architecture for a Minesweeper game:
Main components:
GUI: Graphical user interface
TextUi: Textual user interface
ATD: An automated test driver used for testing the game logic
Logic: Computation and logic of the game
Store: Storage and retrieval of game data (high scores etc.)
The architecture is typically designed by the software architect, who provides the technical vision of the system and makes high-level (i.e. architecture-level) technical decisions about the project.
Exercises:
Statements about architecture
Can explain Software Architecture
Design → Architecture → Introduction →
What
The software architecture of a program or computing system is the structure or structures of the system, which comprise software elements, the externally visible properties of those elements, and the relationships among them. Architecture is concerned with the public side of interfaces; private details of elements—details having to do solely with internal implementation—are not architectural.
--- Software Architecture in Practice (2nd edition), Bass, Clements, and Kazman
The software architecture shows the overall organization of the system and can be viewed as a very high-level design. It usually consists of a set of interacting components that fit together to achieve the required functionality. It should be a simple and technically viable structure that is well-understood and agreed-upon by everyone in the development team, and it forms the basis for the implementation.
A possible architecture for a Minesweeper game:
Main components:
GUI: Graphical user interface
TextUi: Textual user interface
ATD: An automated test driver used for testing the game logic
Logic: Computation and logic of the game
Store: Storage and retrieval of game data (high scores etc.)
The architecture is typically designed by the software architect, who provides the technical vision of the system and makes high-level (i.e. architecture-level) technical decisions about the project.
Exercises:
Statements about architecture
+-- Software Architecture in Practice (2nd edition), Bass, Clements, and Kazman
The software architecture shows the overall organization of the system and can be viewed as a very high-level design. It usually consists of a set of interacting components that fit together to achieve the required functionality. It should be a simple and technically viable structure that is well-understood and agreed-upon by everyone in the development team, and it forms the basis for the implementation.
A possible architecture for a Minesweeper game:
Main components:
GUI: Graphical user interface
TextUi: Textual user interface
ATD: An automated test driver used for testing the game logic
Logic: Computation and logic of the game
Store: Storage and retrieval of game data (high scores etc.)
The architecture is typically designed by the software architect, who provides the technical vision of the system and makes high-level (i.e. architecture-level) technical decisions about the project.
Exercises:
Statements about architecture
Can improve code quality using technique: avoid empty catch blocks
Avoid empty catch statements, as they are a way to ignore errors silently (which is not a good thing). In cases when it is unavoidable, at least give a comment to explain why the catch block is left empty.
+
Avoid empty catch blocks
Avoid empty catch statements, as they are a way to ignore errors silently (which is not a good thing). In cases when it is unavoidable, at least give a comment to explain why the catch block is left empty.
Can improve code quality using technique: delete dead code
Get rid of unused code the moment it becomes redundant. You might feel reluctant to delete code you have painstakingly written, even if you have no use for that code anymore ("I spent a lot of time writing that code; what if I need it again?"). Consider all code as baggage you have to carry. If you need that code again, simply recover it from the revision control tool you are using. Deleting code you wrote previously is a sign that you are improving.
+
Delete dead code
Get rid of unused code the moment it becomes redundant. You might feel reluctant to delete code you have painstakingly written, even if you have no use for that code anymore ("I spent a lot of time writing that code; what if I need it again?"). Consider all code as baggage you have to carry. If you need that code again, simply recover it from the revision control tool you are using. Deleting code you wrote previously is a sign that you are improving.
Can improve code quality using technique: minimize scope of variables
Minimize global variables. Global variables may be the most convenient way to pass information around, but they do create implicit links between code segments that use the global variable. Avoid them as much as possible.
Define variables in the least possible scope. For example, if the variable is used only within the if block of the conditional statement, it should be declared inside that if block.
The most powerful technique for minimizing the scope of a local variable is to declare it where it is first used.-- Effective Java, by Joshua Bloch
Can improve code quality using technique: minimize code duplication
Code duplication, especially when you copy-paste-modify code, often indicates a poor quality implementation. While it may not be possible to have zero duplication, always think twice before duplicating code; most often there is a better alternative.
This guideline is closely related to the DRY Principle.
+
Intermediate
Minimize scope of variables
Can improve code quality using technique: minimize scope of variables
Minimize global variables. Global variables may be the most convenient way to pass information around, but they do create implicit links between code segments that use the global variable. Avoid them as much as possible.
Define variables in the least possible scope. For example, if the variable is used only within the if block of the conditional statement, it should be declared inside that if block.
The most powerful technique for minimizing the scope of a local variable is to declare it where it is first used.-- Effective Java, by Joshua Bloch
Can improve code quality using technique: minimize code duplication
Code duplication, especially when you copy-paste-modify code, often indicates a poor quality implementation. While it may not be possible to have zero duplication, always think twice before duplicating code; most often there is a better alternative.
This guideline is closely related to the DRY Principle.
Can improve code quality using technique: minimize code duplication
Code duplication, especially when you copy-paste-modify code, often indicates a poor quality implementation. While it may not be possible to have zero duplication, always think twice before duplicating code; most often there is a better alternative.
This guideline is closely related to the DRY Principle.
+
Minimize code duplication
Code duplication, especially when you copy-paste-modify code, often indicates a poor quality implementation. While it may not be possible to have zero duplication, always think twice before duplicating code; most often there is a better alternative.
This guideline is closely related to the DRY Principle.
Can improve code quality using technique: minimize scope of variables
Minimize global variables. Global variables may be the most convenient way to pass information around, but they do create implicit links between code segments that use the global variable. Avoid them as much as possible.
Define variables in the least possible scope. For example, if the variable is used only within the if block of the conditional statement, it should be declared inside that if block.
The most powerful technique for minimizing the scope of a local variable is to declare it where it is first used.-- Effective Java, by Joshua Bloch
Minimize global variables. Global variables may be the most convenient way to pass information around, but they do create implicit links between code segments that use the global variable. Avoid them as much as possible.
Define variables in the least possible scope. For example, if the variable is used only within the if block of the conditional statement, it should be declared inside that if block.
The most powerful technique for minimizing the scope of a local variable is to declare it where it is first used.-- Effective Java, by Joshua Bloch
It is safer to use language constructs in the way they are meant to be used, even if the language allows shortcuts. Such coding practices are common sources of bugs. Know them and avoid them.
+
Introduction
It is safer to use language constructs in the way they are meant to be used, even if the language allows shortcuts. Such coding practices are common sources of bugs. Know them and avoid them.
Can explain the need for commenting minimally but sufficiently
Implementation → Code Quality → Comments →
-
Introduction
Good code is its own best documentation. As you’re about to add a comment, ask yourself, ‘How can I improve the code so that this comment isn’t needed?’ Improve the code and then document it to make it even clearer. -- Steve McConnell, Author of Clean Code
Some think commenting heavily increases the 'code quality'. That is not so. Avoid writing comments to explain bad code. Improve the code to make it self-explanatory.
+
Introduction
Good code is its own best documentation. As you’re about to add a comment, ask yourself, ‘How can I improve the code so that this comment isn’t needed?’ Improve the code and then document it to make it even clearer. -- Steve McConnell, Author of Clean Code
Some think commenting heavily increases the 'code quality'. That is not so. Avoid writing comments to explain bad code. Improve the code to make it self-explanatory.
One essential way to improve code quality is to follow a consistent style. That is why software engineers usually follow a strict coding standard (aka style guide).
The aim of a coding standard is to make the entire codebase look like it was written by one person. A coding standard is usually specific to a programming language and specifies guidelines such as the locations of opening and closing braces, indentation styles and naming styles (e.g. whether to use Hungarian style, Pascal casing, Camel casing, etc.). It is important that the whole team/company uses the same coding standard and that the standard is generally not inconsistent with typical industry practices. If a company's coding standard is very different from what is typically used in the industry, new recruits will take longer to get used to the company's coding style.
IDEs can help to enforce some parts of a coding standard e.g. indentation rules.
Exercises:
What is the recommended approach regarding coding standards?
One essential way to improve code quality is to follow a consistent style. That is why software engineers usually follow a strict coding standard (aka style guide).
The aim of a coding standard is to make the entire codebase look like it was written by one person. A coding standard is usually specific to a programming language and specifies guidelines such as the locations of opening and closing braces, indentation styles and naming styles (e.g. whether to use Hungarian style, Pascal casing, Camel casing, etc.). It is important that the whole team/company uses the same coding standard and that the standard is generally not inconsistent with typical industry practices. If a company's coding standard is very different from what is typically used in the industry, new recruits will take longer to get used to the company's coding style.
IDEs can help to enforce some parts of a coding standard e.g. indentation rules.
Exercises:
What is the recommended approach regarding coding standards?
One essential way to improve code quality is to follow a consistent style. That is why software engineers usually follow a strict coding standard (aka style guide).
The aim of a coding standard is to make the entire codebase look like it was written by one person. A coding standard is usually specific to a programming language and specifies guidelines such as the locations of opening and closing braces, indentation styles and naming styles (e.g. whether to use Hungarian style, Pascal casing, Camel casing, etc.). It is important that the whole team/company uses the same coding standard and that the standard is generally not inconsistent with typical industry practices. If a company's coding standard is very different from what is typically used in the industry, new recruits will take longer to get used to the company's coding style.
IDEs can help to enforce some parts of a coding standard e.g. indentation rules.
Exercises:
What is the recommended approach regarding coding standards?
+
Introduction
One essential way to improve code quality is to follow a consistent style. That is why software engineers usually follow a strict coding standard (aka style guide).
The aim of a coding standard is to make the entire codebase look like it was written by one person. A coding standard is usually specific to a programming language and specifies guidelines such as the locations of opening and closing braces, indentation styles and naming styles (e.g. whether to use Hungarian style, Pascal casing, Camel casing, etc.). It is important that the whole team/company uses the same coding standard and that the standard is generally not inconsistent with typical industry practices. If a company's coding standard is very different from what is typically used in the industry, new recruits will take longer to get used to the company's coding style.
IDEs can help to enforce some parts of a coding standard e.g. indentation rules.
Exercises:
What is the recommended approach regarding coding standards?
Can explain the importance of code quality
Implementation → Code Quality → Introduction →
-
What
Always code as if the person who ends up maintaining your code will be a violent psychopath who knows where you live. -- Martin Golding
Production code needs to be of high quality. Given how the world is becoming increasingly dependent on software, poor quality code is something no one can afford to tolerate.
+
What
Always code as if the person who ends up maintaining your code will be a violent psychopath who knows where you live. -- Martin Golding
Production code needs to be of high quality. Given how the world is becoming increasingly dependent on software, poor quality code is something no one can afford to tolerate.
Implementation → Code Quality →
-
Introduction
What
Can explain the importance of code quality
Always code as if the person who ends up maintaining your code will be a violent psychopath who knows where you live. -- Martin Golding
Production code needs to be of high quality. Given how the world is becoming increasingly dependent on software, poor quality code is something no one can afford to tolerate.
+
Introduction
What
Can explain the importance of code quality
Always code as if the person who ends up maintaining your code will be a violent psychopath who knows where you live. -- Martin Golding
Production code needs to be of high quality. Given how the world is becoming increasingly dependent on software, poor quality code is something no one can afford to tolerate.
Can improve code quality using technique: avoid long methods
Avoid long methods as they often contain more information than what the reader can process at a time. Consider if shortening is possible when a method goes beyond 30 . The bigger the haystack, the harder it is to find a needle.
+
Avoid long methods
Avoid long methods as they often contain more information than what the reader can process at a time. Consider if shortening is possible when a method goes beyond 30 . The bigger the haystack, the harder it is to find a needle.
Can improve code quality using technique: make the code obvious
Make the code as explicit as possible, even if the language syntax allows them to be implicit. Here are some examples:
[Java] Use explicit type conversion instead of implicit type conversion.
[Java, Python] Use parentheses/braces to show groupings even when they can be skipped.
[Java, Python] Use enumerations when a certain variable can take only a small number of finite values. For example, instead of declaring the variable 'state' as an integer and using values 0, 1, 2 to denote the states 'starting', 'enabled', and 'disabled' respectively, declare 'state' as type SystemState and define an enumeration SystemState that has values 'STARTING', 'ENABLED', and 'DISABLED'.
+
Make the code obvious
Make the code as explicit as possible, even if the language syntax allows them to be implicit. Here are some examples:
[Java] Use explicit type conversion instead of implicit type conversion.
[Java, Python] Use parentheses/braces to show groupings even when they can be skipped.
[Java, Python] Use enumerations when a certain variable can take only a small number of finite values. For example, instead of declaring the variable 'state' as an integer and using values 0, 1, 2 to denote the states 'starting', 'enabled', and 'disabled' respectively, declare 'state' as type SystemState and define an enumeration SystemState that has values 'STARTING', 'ENABLED', and 'DISABLED'.
Can improve code quality using technique: avoid premature optimizations
Optimizing code prematurely has several drawbacks:
You may not know which parts are the real performance bottlenecks. This is especially the case when the code undergoes transformations (e.g. compiling, minifying, transpiling, etc.) before it becomes an executable. Ideally, you should use a profiler tool to identify the actual bottlenecks of the code first, and optimize only those parts.
Optimizing can complicate the code, affecting correctness and readability.
Hand-optimized code can be harder for the compiler to optimize (the simpler the code, the easier it is for the compiler to optimize). In many cases, a compiler can do a better job of optimizing the runtime code if you don't get in the way by trying to hand-optimize the source code.
Make it work, make it right, make it fast is popular saying in the industry, which means in most cases, getting the code to perform correctly should take priority over optimizing it. If the code doesn't work correctly, it has no value no matter how fast/efficient it is.
Premature optimization is the root of all evil in programming. -- Donald Knuth
Of course, there are cases in which optimizing takes priority over other thingse.g. when writing code for resource-constrained environments. This guideline is simply a caution that you should optimize only when it is really needed.
+
Avoid premature optimizations
Optimizing code prematurely has several drawbacks:
You may not know which parts are the real performance bottlenecks. This is especially the case when the code undergoes transformations (e.g. compiling, minifying, transpiling, etc.) before it becomes an executable. Ideally, you should use a profiler tool to identify the actual bottlenecks of the code first, and optimize only those parts.
Optimizing can complicate the code, affecting correctness and readability.
Hand-optimized code can be harder for the compiler to optimize (the simpler the code, the easier it is for the compiler to optimize). In many cases, a compiler can do a better job of optimizing the runtime code if you don't get in the way by trying to hand-optimize the source code.
Make it work, make it right, make it fast is popular saying in the industry, which means in most cases, getting the code to perform correctly should take priority over optimizing it. If the code doesn't work correctly, it has no value no matter how fast/efficient it is.
Premature optimization is the root of all evil in programming. -- Donald Knuth
Of course, there are cases in which optimizing takes priority over other thingse.g. when writing code for resource-constrained environments. This guideline is simply a caution that you should optimize only when it is really needed.
Can improve code quality using technique: do not 'trip up' reader
Do not try to write ‘clever’ code. "Keep it simple, stupid” (KISS), as the old adage goes. For example, do not dismiss the brute-force yet simple solution in favor of a complicated one because of some ‘supposed benefits’ such as 'better reusability' unless you have a strong justification.
Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it. -- Brian W. Kernighan
Programs must be written for people to read, and only incidentally for machines to execute. -- Abelson and Sussman
+
Practice KISSing
Do not try to write ‘clever’ code. "Keep it simple, stupid” (KISS), as the old adage goes. For example, do not dismiss the brute-force yet simple solution in favor of a complicated one because of some ‘supposed benefits’ such as 'better reusability' unless you have a strong justification.
Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it. -- Brian W. Kernighan
Programs must be written for people to read, and only incidentally for machines to execute. -- Abelson and Sussman
Can explain the importance of readability
Implementation → Code Quality → Readability →
-
Introduction
Programs should be written and polished until they acquire publication quality. --Niklaus Wirth
Among various dimensions of code quality, such as run-time efficiency, security, and robustness, one of the most important is readability (aka understandability). This is because in any non-trivial software project, code needs to be read, understood, and modified by other developers later on. Even if you do not intend to pass the code to someone else, code quality is still important because you will become a 'stranger' to your own code someday.
+
Introduction
Programs should be written and polished until they acquire publication quality. --Niklaus Wirth
Among various dimensions of code quality, such as run-time efficiency, security, and robustness, one of the most important is readability (aka understandability). This is because in any non-trivial software project, code needs to be read, understood, and modified by other developers later on. Even if you do not intend to pass the code to someone else, code quality is still important because you will become a 'stranger' to your own code someday.
Can improve code quality using technique: use standard words
Use correct spelling in names. Avoid 'texting-style' spelling. Avoid foreign language words, slang, and names that are only meaningful within specific contexts/timese.g. terms from private jokes, a TV show currently popular in your country.
+
Use standard words
Use correct spelling in names. Avoid 'texting-style' spelling. Avoid foreign language words, slang, and names that are only meaningful within specific contexts/timese.g. terms from private jokes, a TV show currently popular in your country.
Can improve code quality using technique: avoid misleading names
Related things should be named similarly, while unrelated things should NOT.
Example: Consider these variables
colorBlack: hex value for color black
colorWhite: hex value for color white
colorBlue: number of times blue is used
hexForRed: hex value for color red
This is misleading because colorBlue is named similar to colorWhite and colorBlack but has a different purpose while hexForRed is named differently but has a very similar purpose to the first two variables. The following is better:
hexForBlackhexForWhitehexForRed
blueColorCount
Avoid misleading or ambiguous names (e.g. those with multiple meanings), similar sounding names, hard-to-pronounce ones (e.g. avoid ambiguities like "is that a lowercase L, capital I or number 1?", or "is that number 0 or letter O?"), almost similar names.
Bad
Good
Reason
phase0
phaseZero
Is that zero or letter O?
rwrLgtDirn
rowerLegitDirection
Hard to pronounce
rightleftwrong
rightDirectionleftDirectionwrongResponse
right is for 'correct' or 'opposite of 'left'?
redBooksreadBooks
redColorBooksbooksRead
red and read (past tense) sounds the same
FiletMignon
egg
If the requirement is just a name of a food, egg is a much easier to type/say choice than FiletMignon
+
Avoid misleading names
Related things should be named similarly, while unrelated things should NOT.
Example: Consider these variables
colorBlack: hex value for color black
colorWhite: hex value for color white
colorBlue: number of times blue is used
hexForRed: hex value for color red
This is misleading because colorBlue is named similar to colorWhite and colorBlack but has a different purpose while hexForRed is named differently but has a very similar purpose to the first two variables. The following is better:
hexForBlackhexForWhitehexForRed
blueColorCount
Avoid misleading or ambiguous names (e.g. those with multiple meanings), similar sounding names, hard-to-pronounce ones (e.g. avoid ambiguities like "is that a lowercase L, capital I or number 1?", or "is that number 0 or letter O?"), almost similar names.
Bad
Good
Reason
phase0
phaseZero
Is that zero or letter O?
rwrLgtDirn
rowerLegitDirection
Hard to pronounce
rightleftwrong
rightDirectionleftDirectionwrongResponse
right is for 'correct' or 'opposite of 'left'?
redBooksreadBooks
redColorBooksbooksRead
red and read (past tense) sounds the same
FiletMignon
egg
If the requirement is just a name of a food, egg is a much easier to type/say choice than FiletMignon
Implementation → Code Quality → Naming →
-
Intermediate
Use name to explain
Can improve code quality using technique: use name to explain
A name is not just for differentiation; it should explain the named entity to the reader accurately and at a sufficient level of detail.
Bad
Good
processInput() (what 'process'?)
removeWhiteSpaceFromInput()
flag
isValidInput
temp
If a name has multiple words, they should be in a sensible order.
Bad
Good
bySizeOrder()
orderBySize()
Imagine going to the doctor's and saying "My eye1 is swollen"! Don’t use numbers or case to distinguish names.
Bad
Bad
Good
value1, value2
value, Value
originalValue, finalValue
Not too long, not too short
Can improve code quality using technique: not too long, not too short
While it is preferable not to have lengthy names, names that are 'too short' are even worse. If you must abbreviate or use acronyms, do it consistently. Explain their full meaning at an obvious location.
Avoid misleading names
Can improve code quality using technique: avoid misleading names
Related things should be named similarly, while unrelated things should NOT.
Example: Consider these variables
colorBlack: hex value for color black
colorWhite: hex value for color white
colorBlue: number of times blue is used
hexForRed: hex value for color red
This is misleading because colorBlue is named similar to colorWhite and colorBlack but has a different purpose while hexForRed is named differently but has a very similar purpose to the first two variables. The following is better:
hexForBlackhexForWhitehexForRed
blueColorCount
Avoid misleading or ambiguous names (e.g. those with multiple meanings), similar sounding names, hard-to-pronounce ones (e.g. avoid ambiguities like "is that a lowercase L, capital I or number 1?", or "is that number 0 or letter O?"), almost similar names.
Bad
Good
Reason
phase0
phaseZero
Is that zero or letter O?
rwrLgtDirn
rowerLegitDirection
Hard to pronounce
rightleftwrong
rightDirectionleftDirectionwrongResponse
right is for 'correct' or 'opposite of 'left'?
redBooksreadBooks
redColorBooksbooksRead
red and read (past tense) sounds the same
FiletMignon
egg
If the requirement is just a name of a food, egg is a much easier to type/say choice than FiletMignon
+
Intermediate
Use name to explain
Can improve code quality using technique: use name to explain
A name is not just for differentiation; it should explain the named entity to the reader accurately and at a sufficient level of detail.
Bad
Good
processInput() (what 'process'?)
removeWhiteSpaceFromInput()
flag
isValidInput
temp
If a name has multiple words, they should be in a sensible order.
Bad
Good
bySizeOrder()
orderBySize()
Imagine going to the doctor's and saying "My eye1 is swollen"! Don’t use numbers or case to distinguish names.
Bad
Bad
Good
value1, value2
value, Value
originalValue, finalValue
Not too long, not too short
Can improve code quality using technique: not too long, not too short
While it is preferable not to have lengthy names, names that are 'too short' are even worse. If you must abbreviate or use acronyms, do it consistently. Explain their full meaning at an obvious location.
Avoid misleading names
Can improve code quality using technique: avoid misleading names
Related things should be named similarly, while unrelated things should NOT.
Example: Consider these variables
colorBlack: hex value for color black
colorWhite: hex value for color white
colorBlue: number of times blue is used
hexForRed: hex value for color red
This is misleading because colorBlue is named similar to colorWhite and colorBlack but has a different purpose while hexForRed is named differently but has a very similar purpose to the first two variables. The following is better:
hexForBlackhexForWhitehexForRed
blueColorCount
Avoid misleading or ambiguous names (e.g. those with multiple meanings), similar sounding names, hard-to-pronounce ones (e.g. avoid ambiguities like "is that a lowercase L, capital I or number 1?", or "is that number 0 or letter O?"), almost similar names.
Bad
Good
Reason
phase0
phaseZero
Is that zero or letter O?
rwrLgtDirn
rowerLegitDirection
Hard to pronounce
rightleftwrong
rightDirectionleftDirectionwrongResponse
right is for 'correct' or 'opposite of 'left'?
redBooksreadBooks
redColorBooksbooksRead
red and read (past tense) sounds the same
FiletMignon
egg
If the requirement is just a name of a food, egg is a much easier to type/say choice than FiletMignon
Can improve code quality using technique: not too long, not too short
While it is preferable not to have lengthy names, names that are 'too short' are even worse. If you must abbreviate or use acronyms, do it consistently. Explain their full meaning at an obvious location.
+
Not too long, not too short
While it is preferable not to have lengthy names, names that are 'too short' are even worse. If you must abbreviate or use acronyms, do it consistently. Explain their full meaning at an obvious location.
Can improve code quality using technique: use name to explain
This section uses extracts from the -- Java Tutorial, with some adaptations.
A collection — sometimes called a container — is simply an object that groups multiple elements into a single unit. Collections are used to store, retrieve, manipulate, and communicate aggregate data.
Typically, collections represent data items that form a natural group, such as a poker hand (a collection of cards), a mail folder (a collection of letters), or a telephone directory (a mapping of names to phone numbers).
The collections framework is a unified architecture for representing and manipulating collections. It contains the following:
Interfaces: These are abstract data types that represent collections. Interfaces allow collections to be manipulated independently of the details of their representation. Example: the List<E> interface can be used to manipulate list-like collections which may be implemented in different ways such as ArrayList<E> or LinkedList<E>.
Implementations: These are the concrete implementations of the collection interfaces. In essence, they are reusable data structures. Example: the ArrayList<E> class implements the List<E> interface while the HashMap<K, V> class implements the Map<K, V> interface.
Algorithms: These are the methods that perform useful computations, such as searching and sorting, on objects that implement collection interfaces. The algorithms are said to be polymorphic: that is, the same method can be used on many different implementations of the appropriate collection interface. Example: the sort(List<E>) method can sort a collection that implements the List<E> interface.
A well-known example of collections frameworks is the C++ Standard Template Library (STL). Although both are collections frameworks and the syntax look similar, note that there are important philosophical and implementation differences between the two.
The following list describes the core collection interfaces:
Collection — the root of the collection hierarchy. A collection represents a group of objects known as its elements. The Collection interface is the least common denominator that all collections implement and is used to pass collections around and to manipulate them when maximum generality is desired. Some types of collections allow duplicate elements, and others do not. Some are ordered and others are unordered. The Java platform doesn't provide any direct implementations of this interface but provides implementations of more specific subinterfaces, such as Set and List. Also see the Collection API.
Set — a collection that cannot contain duplicate elements. This interface models the mathematical set abstraction and is used to represent sets, such as the cards comprising a poker hand, the courses making up a student's schedule, or the processes running on a machine. Also see the Set API.
List — an ordered collection (sometimes called a sequence). Lists can contain duplicate elements. The user of a List generally has precise control over where in the list each element is inserted and can access elements by their integer index (position). Also see the List API.
Queue — a collection used to hold multiple elements prior to processing. Besides basic Collection operations, a Queue provides additional insertion, extraction, and inspection operations. Also see the Queue API.
Map — an object that maps keys to values. A Map cannot contain duplicate keys; each key can map to at most one value. Also see the Map API.
Others: Deque, SortedSet, SortedMap
+
The collections framework
This section uses extracts from the -- Java Tutorial, with some adaptations.
A collection — sometimes called a container — is simply an object that groups multiple elements into a single unit. Collections are used to store, retrieve, manipulate, and communicate aggregate data.
Typically, collections represent data items that form a natural group, such as a poker hand (a collection of cards), a mail folder (a collection of letters), or a telephone directory (a mapping of names to phone numbers).
The collections framework is a unified architecture for representing and manipulating collections. It contains the following:
Interfaces: These are abstract data types that represent collections. Interfaces allow collections to be manipulated independently of the details of their representation. Example: the List<E> interface can be used to manipulate list-like collections which may be implemented in different ways such as ArrayList<E> or LinkedList<E>.
Implementations: These are the concrete implementations of the collection interfaces. In essence, they are reusable data structures. Example: the ArrayList<E> class implements the List<E> interface while the HashMap<K, V> class implements the Map<K, V> interface.
Algorithms: These are the methods that perform useful computations, such as searching and sorting, on objects that implement collection interfaces. The algorithms are said to be polymorphic: that is, the same method can be used on many different implementations of the appropriate collection interface. Example: the sort(List<E>) method can sort a collection that implements the List<E> interface.
A well-known example of collections frameworks is the C++ Standard Template Library (STL). Although both are collections frameworks and the syntax look similar, note that there are important philosophical and implementation differences between the two.
The following list describes the core collection interfaces:
Collection — the root of the collection hierarchy. A collection represents a group of objects known as its elements. The Collection interface is the least common denominator that all collections implement and is used to pass collections around and to manipulate them when maximum generality is desired. Some types of collections allow duplicate elements, and others do not. Some are ordered and others are unordered. The Java platform doesn't provide any direct implementations of this interface but provides implementations of more specific subinterfaces, such as Set and List. Also see the Collection API.
Set — a collection that cannot contain duplicate elements. This interface models the mathematical set abstraction and is used to represent sets, such as the cards comprising a poker hand, the courses making up a student's schedule, or the processes running on a machine. Also see the Set API.
List — an ordered collection (sometimes called a sequence). Lists can contain duplicate elements. The user of a List generally has precise control over where in the list each element is inserted and can access elements by their integer index (position). Also see the List API.
Queue — a collection used to hold multiple elements prior to processing. Besides basic Collection operations, a Queue provides additional insertion, extraction, and inspection operations. Also see the Queue API.
Map — an object that maps keys to values. A Map cannot contain duplicate keys; each key can map to at most one value. Also see the Map API.
Others: Deque, SortedSet, SortedMap
Can use primitive data types
C++ to Java → Data Types →
-
Primitive data types
Java has a number of primitive data types, as given below:
byte: an integer in the range -128 to 127 (inclusive).
short: an integer in the range -32,768 to 32,767 (inclusive).
int: an integer in the range -231 to 231-1.
long: An integer in the range -263 to 263-1.
float: a single-precision 32-bit IEEE 754 floating point. This data type should never be used for precise values, such as currency. For that, you will need to use the java.math.BigDecimal class instead.
double: a double-precision 64-bit IEEE 754 floating point. For decimal values, this data type is generally the default choice. This data type should never be used for precise values, such as currency.
boolean: has only two possible values: true and false.
char: The char data type is a single 16-bit Unicode character. It has a minimum value of '\u0000' (or 0) and a maximum value of '\uffff' (or 65,535 inclusive).
The String type (a peek)
Java has a built-in type called String to represent strings. While String is not a primitive type, strings are used often.String values are demarcated by enclosing in a pair of double quotes (e.g., "Hello"). You can use the + operator to concatenate strings (e.g., "Hello " + "!").
You’ll learn more about strings in a later section.
Java has a number of primitive data types, as given below:
byte: an integer in the range -128 to 127 (inclusive).
short: an integer in the range -32,768 to 32,767 (inclusive).
int: an integer in the range -231 to 231-1.
long: An integer in the range -263 to 263-1.
float: a single-precision 32-bit IEEE 754 floating point. This data type should never be used for precise values, such as currency. For that, you will need to use the java.math.BigDecimal class instead.
double: a double-precision 64-bit IEEE 754 floating point. For decimal values, this data type is generally the default choice. This data type should never be used for precise values, such as currency.
boolean: has only two possible values: true and false.
char: The char data type is a single 16-bit Unicode character. It has a minimum value of '\u0000' (or 0) and a maximum value of '\uffff' (or 65,535 inclusive).
The String type (a peek)
Java has a built-in type called String to represent strings. While String is not a primitive type, strings are used often.String values are demarcated by enclosing in a pair of double quotes (e.g., "Hello"). You can use the + operator to concatenate strings (e.g., "Hello " + "!").
You’ll learn more about strings in a later section.
Given below is an extract from the -- Java Tutorial, with some adaptations.
There are three basic categories of exceptions In Java:
Checked exceptions: exceptional conditions that a well-written application should anticipate and recover from. All exceptions are checked exceptions, except for Error, RuntimeException, and their subclasses.
Suppose an application prompts a user for an input file name, then opens the file by passing the name to the constructor for java.io.FileReader. Normally, the user provides the name of an existing, readable file, so the construction of the FileReader object succeeds, and the execution of the application proceeds normally. But sometimes the user supplies the name of a nonexistent file, and the constructor throws java.io.FileNotFoundException. A well-written program will catch this exception and notify the user of the mistake, possibly prompting for a corrected file name.
Errors: exceptional conditions that are external to the application, and that the application usually cannot anticipate or recover from. Errors are those exceptions indicated by Error and its subclasses.
Suppose that an application successfully opens a file for input, but is unable to read the file because of a hardware or system malfunction. The unsuccessful read will throw java.io.IOError. An application might choose to catch this exception, in order to notify the user of the problem — but it also might make sense for the program to print a stack trace and exit.
Runtime exceptions: conditions that are internal to the application, and that the application usually cannot anticipate or recover from. Runtime exceptions are those indicated by RuntimeException and its subclasses. These usually indicate programming bugs, such as logic errors or improper use of an API.
Consider the application described previously that passes a file name to the constructor for FileReader. If a logic error causes a null to be passed to the constructor, the constructor will throw NullPointerException. The application can catch this exception, but it probably makes more sense to eliminate the bug that caused the exception to occur.
Errors and runtime exceptions are collectively known as unchecked exceptions.
+
What are Exceptions?
Given below is an extract from the -- Java Tutorial, with some adaptations.
There are three basic categories of exceptions In Java:
Checked exceptions: exceptional conditions that a well-written application should anticipate and recover from. All exceptions are checked exceptions, except for Error, RuntimeException, and their subclasses.
Suppose an application prompts a user for an input file name, then opens the file by passing the name to the constructor for java.io.FileReader. Normally, the user provides the name of an existing, readable file, so the construction of the FileReader object succeeds, and the execution of the application proceeds normally. But sometimes the user supplies the name of a nonexistent file, and the constructor throws java.io.FileNotFoundException. A well-written program will catch this exception and notify the user of the mistake, possibly prompting for a corrected file name.
Errors: exceptional conditions that are external to the application, and that the application usually cannot anticipate or recover from. Errors are those exceptions indicated by Error and its subclasses.
Suppose that an application successfully opens a file for input, but is unable to read the file because of a hardware or system malfunction. The unsuccessful read will throw java.io.IOError. An application might choose to catch this exception, in order to notify the user of the problem — but it also might make sense for the program to print a stack trace and exit.
Runtime exceptions: conditions that are internal to the application, and that the application usually cannot anticipate or recover from. Runtime exceptions are those indicated by RuntimeException and its subclasses. These usually indicate programming bugs, such as logic errors or improper use of an API.
Consider the application described previously that passes a file name to the constructor for FileReader. If a logic error causes a null to be passed to the constructor, the constructor will throw NullPointerException. The application can catch this exception, but it probably makes more sense to eliminate the bug that caused the exception to occur.
Errors and runtime exceptions are collectively known as unchecked exceptions.
Can compile a simple Java program
C++ to Java → Getting Started →
-
Compiling a program
To compile the HelloWorld program, open a command console, navigate to the folder containing the file, and run the following command.
>_javac HelloWorld.java
If the compilation is successful, you should see a file HelloWorld.class. That file contains the byte code for your program. If the compilation is unsuccessful, you will be notified of the compile-time errors.
Notes:
javac is the java compiler that you get when you install the JDK.
For the above command to work, your console program should be able to find the javac executable (e.g., In Windows, the location of the javac.exe should be in the PATH system variable). This page shows how to set PATH in different OS'es.
+
Compiling a program
To compile the HelloWorld program, open a command console, navigate to the folder containing the file, and run the following command.
>_javac HelloWorld.java
If the compilation is successful, you should see a file HelloWorld.class. That file contains the byte code for your program. If the compilation is unsuccessful, you will be notified of the compile-time errors.
Notes:
javac is the java compiler that you get when you install the JDK.
For the above command to work, your console program should be able to find the javac executable (e.g., In Windows, the location of the javac.exe should be in the PATH system variable). This page shows how to set PATH in different OS'es.





















































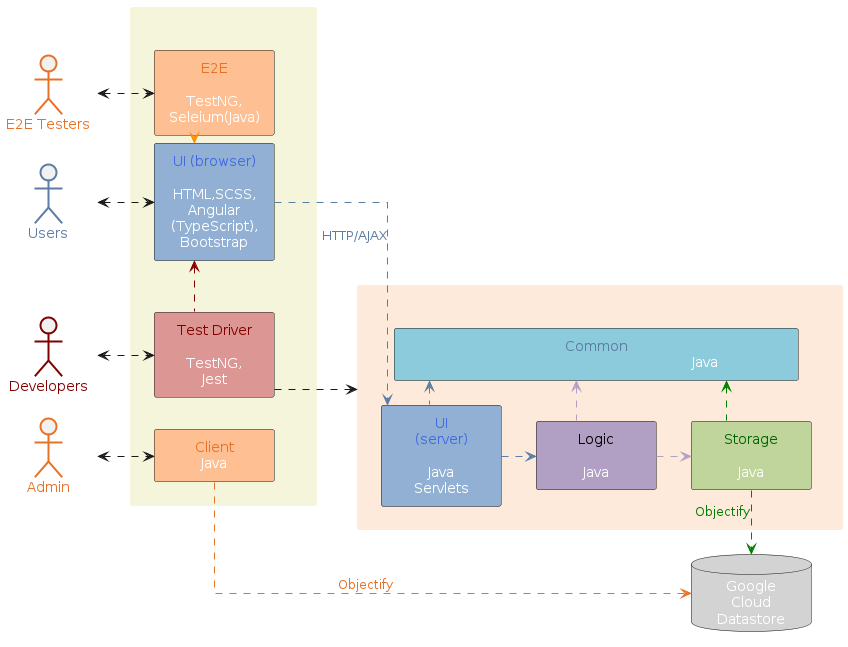
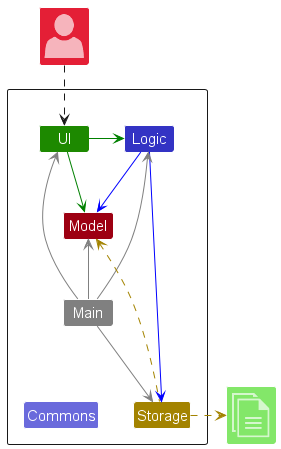






{kind=link}