If you want to contribute, hack or play with Optimus you are in the right place. This is a little guide to
- Install Jupyter Notebooks
Download anaconda from https://www.anaconda.com/download/ and run the file
- Clone the Repo and install requirements
Go to the folder you want to download de repo and run:
git clone https://github.com/hi-primus/optimus.git
The install the requirements
pip install -r requirements.txt
- Install Spark
Go to http://spark.apache.org/downloads.html and download Spark 2.3.1 with Pre-built Hadoop 2.7 Decompress the file in c:\opt\spark
- Install java
First, install chocolatey https://chocolatey.org/install#installing-chocolatey
Chocolatey needs Administrative permission.
Then from the command line
choco install jdk8
Be sure that the Spark version is the same that you download
setx SPARK_HOME C:\opt\spark\spark-2.3.1-bin-hadoop2.7
Check in the console if python is run as 'python','python3' etc. Use the one you found to set PYSPARK_PYTHON
setx PYSPARK_PYTHON python
Open the examples folder in the cloned Optimus repo and go to hack_optimus.ipyn. There you are going fo find some tips to hack and contribute with Optimus
Error: you do not have permission to tmp\hive from anaconda wintools.exe ls c:\tmp\hive wintools.exe chmod 777 c:\tmp\hive
To recreate the templates you need to inline the CSS.
First go to https://nodejs.org and download and install nodejs
From the Optimus repo folder, in the terminal:
- Run
npm install - Run
node inlinecss.js
Sometimes we need to test and modify some files a make test in some environments for example Google DataProc or Databricks. For that we could upload pip package to test.pypi.org so we could test it in the remote environment faster without touching the main repo.
First create the pip package. A dist folder should be create
python setup.py sdist bdist_wheel
Then upload to test.pypi.org. Be sure to create and account
pip install twine
This will prompt your test.pypi.org credentials
python -m twine upload --repository-url https://test.pypi.org/legacy/ dist/*
Now install from test.pypi.org
pip install --index-url https://test.pypi.org/simple pyoptimus --no-deps
Upload to pyoptimus
twine upload dist/*
pip install --upgrade --no-deps --force-reinstall git+https://github.com/hi-primus/[email protected]
This file can not be found to download and must be compiled.
Reference https://www.javahelps.com/2017/10/install-apache-maven-on-linux.html
Download spark-redis from GitHub https://github.com/RedisLabs/spark-redis (either git clone or download as a zip), and build it using Maven.
$ cd spark-redis
$ mvn clean package -DskipTests
Because GPUs are not very common you may want to use some external server like AWS, GCP or Azure. Here the workflow.
https://github.com/hi-primus/optimus.git
cd Optimus
git checkout develop-23.5
From PyCharm create a Deployment using a private key and point it to you Optimus folder in the server Be sure to create a mapping so you can sync the local files with the remote server More info about Mappings here https://www.jetbrains.com/help/pycharm/accessing-files-on-remote-hosts.html Also click Tools-> Deployment -> Automatic uploads When you press press Ctrl + S the file will be uploaded
In the server be sure to install in the conda environment
conda install pip
cd Optimus
pip install -r requirements.txt
For configuring a local server
On Digital Ocean
sudo apt-get update
sudo apt-get install -y python3-pip
sudo apt install libz-dev libssl-dev libcurl4-gnutls-dev libexpat1-dev gettext cmake gcc
pip install --upgrade --force-reinstall git+https://github.com/hi-primus/[email protected]
pip install dask[complete]
Run tmux to launch the scheduler and the worker. Use the 'a' param to attach to and already created session.
tmux a
Use Ctrl + B + C to create a new window, Ctrl + B + N to go to the next window
dask scheduler
dask worker 127.0.0.0.1 --nthreads=8
Be sure to install the external libraries in the remote server. You can clone the repo
git clone https://github.com/hi-primus/optimus.git
and run
pip install -r requirements.txt
The main way to work in Optimus is using .cols and .rows.
.cols is going to get and process data in a vertical way .rows in vertical.
You can add functions to any engine:
- Pandas
- Dask
- cuDF
- Dask-cuDF
- Spark
- Vaex
- Ibis
For example, if a new function needs to be added to Pandas and Dask you can add them to optimus/engines/pandas/columns.py and optimus/engines/dask/columns.py in case it has different implementations, but since both uses the same API we could implement it in:
optimus/engines/base/pandas/columns.py
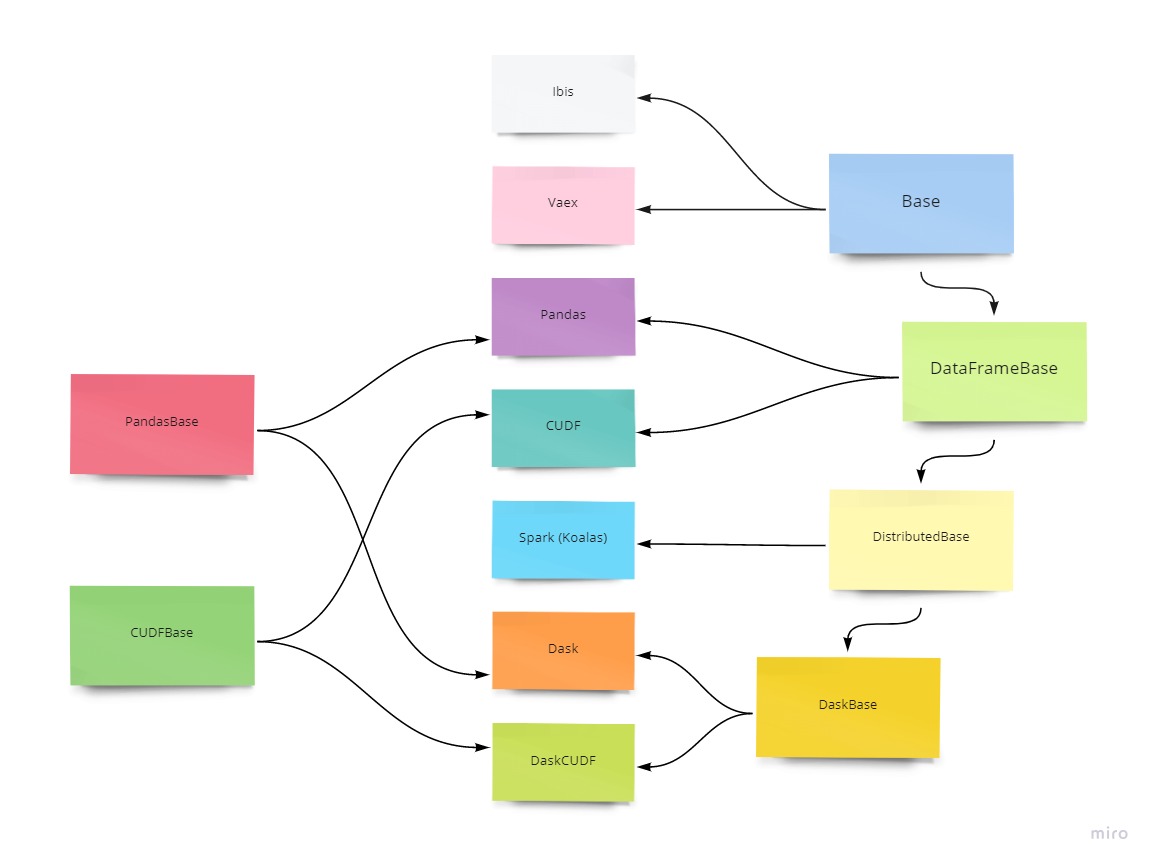
In some cases the same code can be used for multiple engines. We organize Optimus to extend from:
- Base. Common to all the implementations. Use this in case no internal operations are made.
- DataFrameBase. Common to Pandas, cuDF, Dask, Dask-cuDF and Spark (that uses Koalas).
- DistributedBase. Common to all the distributed implementations like Dask, Dask-cuDF and Spark.
- DaskBase. Common to all the dask-based implementations like Dask and Dask-cuDF.
- PandasBase. Common to Pandas, Dask and Spark.
- CUDFBase. Common to cuDF and Dask-cuDF.
This applies to:
- Dataframe operations at
optimus/engines/**/dataframe.py - Column operations at
optimus/engines/**/columns.py - Rows operations at
optimus/engines/**/rows.py - Mask operations at
optimus/engines/**/mask.py - Set operations at
optimus/engines/**/set.py: "set to mask" operations. - Functions at
optimus/engines/**/functions.py: internal functions applied to the internal dataframe, normally used ondf.cols.apply - Constants at
optimus/engines/**/constants.py - Create operations at
optimus/engines/**/create.py: used inop.create.*()functions. - Load operations at
optimus/engines/**/io/load.py: used inop.load.*()functions. - Save operations at
optimus/engines/**/io/save.py
One common job inside a function is handling what columns are going to be processed and where we are going to put the output data.
For this, we create optimus.helpers.columns.prepare_columns which give tools to developer to get the output colums.
See prepare_columns for more info
Always try to use the same Optimus functions to write the functions so it can be reused for all the engines.
For Dask you need to install some additional libraries to interact with databases
>> sudo apt install default-libmysqlclient-dev
>> pip install mysqlclient
pip install --user psycopg2-binary
Install Visual Studio Build Tools. Look at this SO post https://stackoverflow.com/questions/41724445/python-pip-on-windows-command-cl-exe-failed
Add this to the path var env
C:\Program Files (x86)\Microsoft Visual Studio\2019\BuildTools\VC\Tools\MSVC\14.24.28314\bin\Hostx86\x86
C:\Program Files (x86)\Windows Kits\10\Include\10.0.18362.0\ucrt
string-group library is not available in conda so we need to use grayskull to generate the conda recipe
conda intall grayskull
grayskull pypi string-grouper
From Anaconda Prompt
To auto upload the package after the build you can use. NOTE: This can throw an permission error on Windows
conda config --set anaconda_upload yes
Go to
conda create -n optimusbuild python=3.7
conda activate optimusbuild
conda install conda-build
cd /conda/recipes/
conda-build optimus -c rapidsai -c nvidia -c conda-forge -c defaults -c h2oai
Search for the message
anaconda upload xxxxxx\Anaconda3\envs\optimusbuild\conda-bld\noarch\optimus-23.5.0-py_0.tar.bz2
then upload the package to Anaconda
conda install anaconda-client
anaconda login
anaconda upload -u optimus xxxxxx\Anaconda3\envs\optimusbuild\conda-bld\noarch\optimus-23.5.0-py_0.tar.bz2
use your anaconda credentials for https://anaconda.org/
Go to https://anaconda.org/ and check the file is available
conda install -c conda-forge -c argenisleon optimus
pip install mysqlclient
##ODBC
Search for odbc and look for ODBC Data Sources
Bumblebee is just the frontend that interacts with Optimus via Jupyter Kernel Gateway. Bumblebee just sends python code that is executed by Jupyter. Bumblebee does not do any operation over the data. Just receive data a present it to the user. Optimus is the python library that connects to Dask, cudf, Spark to process data. Bumblebee is a frontend interface to present data in a way that can be easily handled by the user.
Install Jupyter Gateway
conda install -c conda-forge jupyter_kernel_gateway
Dask try to infer the column datatype for every partition so it can cause problem the inferred datatype does not match.
Optimus will always parse the columns as object and the try to optimize the data type using the .ext.optimize function.
jupyter kernelspec list
If you want to upgrade a RAPIDS use conda install and remove the create channel from the RAPIDS instructions
conda create -n rapids-0.19 -c rapidsai -c nvidia -c conda-forge rapids-blazing=0.19 python=3.7 cudatoolkit=11.0
conda install -c rapidsai -c nvidia -c conda-forge rapids-blazing=0.19 python=3.7 cudatoolkit=11.0
conda env remove --name project-env
Process 1 input column/1 output column 1 input column/multiple output columns multiple input columns/1 output column multiple input columns/multiple output column
Every engine seems to have multiple implementation and capabilities for handling UDF.
Cudf https://rapidsai.github.io/projects/cudf/en/0.10.0/guide-to-udfs.html
Spark https://spark.apache.org/docs/latest/sql-pyspark-pandas-with-arrow.html
Install sphynx
pip install sphynx
Install the read the docs theme
pip install sphinx_rtd_theme
go to docs/ in the package and run make html