The datadrivenmodel repository has added support for a variety of statistical and machine learning forecasting models and featurizers (such as time-axes encoders). These models come as part of the integration with the open-source darts library, but have been re-implemented in a way that allows for easy integration with datasets that arise in reinforcement learning.
- Support for torch forecasting models
- Data loaders from csv
- Training scripts with
ddm_trainer.py - Prediction scripts with
ddm_predictor.py
- Evaluation scripts with
ddm_train_evaluate.ipynb - Support for time series evaluation metrics
- Encoders for features
- Hyperparmaeter sweeping
[ ]Support for concatenation or padding fromdataclass.py[ ]Diff state support fromdataclass.py
Both of the above features would need to be added directly to the darts.timeseries method in order to utilize the predict method properly.
In order to mitigate unnecessary overlap with other models, the time series models utilize a separate model class implemented in timeseriesclass.py. This class is a wrapper around the darts models, and is designed to be used in the same way as the other models in the repository, i.e., it implements the necessary fit, predict, and predit_sequentially methods that allows for it to be used with the standard ddm_trainer.py and ddm_predictor.py scripts.
Fundamentally, the class TimeSeriesDarts from the timeseriesclass.py script provides the entrypoint to create and load the datasets needed for time series modeling (which has a different structure than standard numpy or pandas objects), build the model with specific hyperparameters (i.e., modify the architecture), fit the model with specific training parameters (i.e., training epochs), and then predict it with adjustable prediction parameters (i.e., prediction horizon).
We recommend you take a look at the corresponding documentation in the darts library, as it will provide comprehensive descriptions of each model and their hyperparameters.
Here is a simple example of how the TimeSeriesDarts class works:
darts_model = TimeSeriesDarts()
train_df, test_df = darts_model.load_from_csv(
dataset_path,
episode_col,
iteration_col,
label_cols,
feature_cols,
0.2,
return_ts=False,
)
nhits_params = {
"input_chunk_length": 7,
# input_chunk_length resolves to how far back to look during training
# should be greater than the smallest
# number of iterations across episodes
"output_chunk_length": 1,
# "pl_trainer_kwargs": {"accelerator": "gpu", "gpus": -1, "auto_select_gpus": True}
}
fit_params = {"epochs": 1}
predict_params = {"n": 1}
darts_model.build_model(model_type="nhits", build_params=nhits_params)
darts_model.fit(train_df, fit_params)
yhat = darts_model.predict(test_df, predict_params)The first step instantiates the TimeSeriesDarts class, and points to a variable. We then utilize the load_from_csv method to load existing data into a set of TimeSeries data objects.
Next, we build our model with specific hyperparameters. In this case, we are building an N-Hits model, and specifying the input_chunk_length which specifies the input history to use for training, and the output_chunk_length, which specifies the prediction horizon to use during training (i.e., the number of predicted samples that are generated for each training sample to check the loss).
We then fit the model with the fit method, and specify the number of training epochs. Here for demonstration purposes we kept a very small number of epochs, but typically you would want to train for a much longer period of time. Note that if you are training a large model, you should consider utilizing a CUDA-enabled GPU to accelerate training. Additional parameters for GPU-based training can be specified using the pl_training_kwargs in the build_params object.
Finally, we predict the model with the predict method, and specify the prediction horizon. In this case, we are predicting the next 1 sample, as we will typically change the action at every iteration and feed it to the next iteration's prediction (along with the new predicted states). Moreover, in our case the test object we are using is a dataframe of many test-episodes. Our implementation of the prediction method will notice this and automatically split the dataset into separate predictions and predict each episode separately and concatenate the results (you will get back a list of
It is worth emphasizing the distinction between how our time series methods utilize past history with input_chunk_length and our previous models do with concatenate_features.
The time series models we have implemented here are all multivariate time series models with covariates support, which means they predict one or many output time series, and can utilize other independent variables as features to inform the next step prediction.
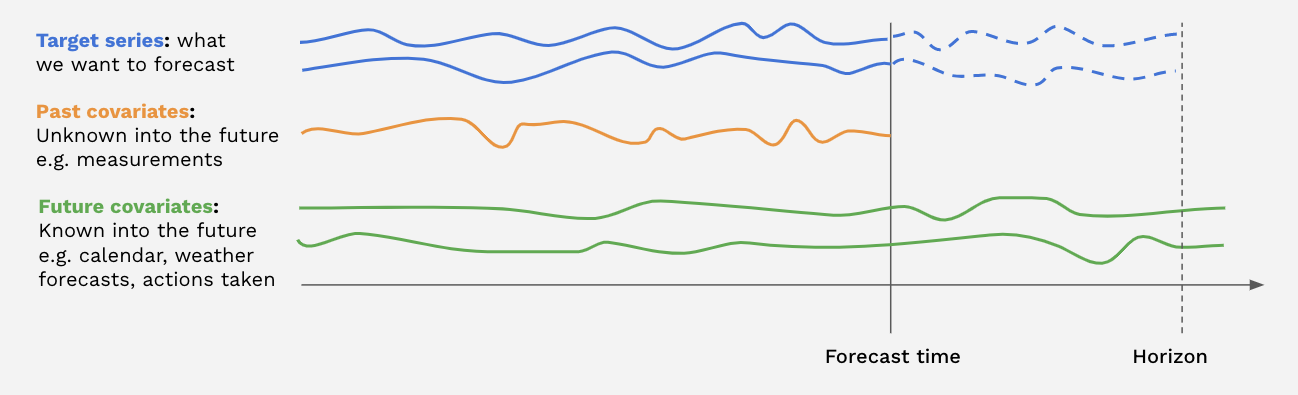
In the above figure, the blue series indicates the series we want to predict, and the orange series indicates the series we are using as features. In our use-case, the blue series will typically be the states of our environment, and the orange series will be actions and episode configuration (note that episode configurations could also be specified as static_covariates, but not all models in the darts library have support for these). It is also possible to include future covariates, which are series whose values are known up to the end of the episode horizon (i.e., static values or already forecasted values). For simplicity, our implementation does not utilize future covariates, but only past covariates.
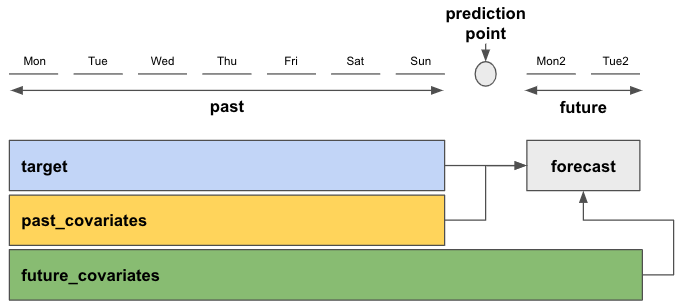
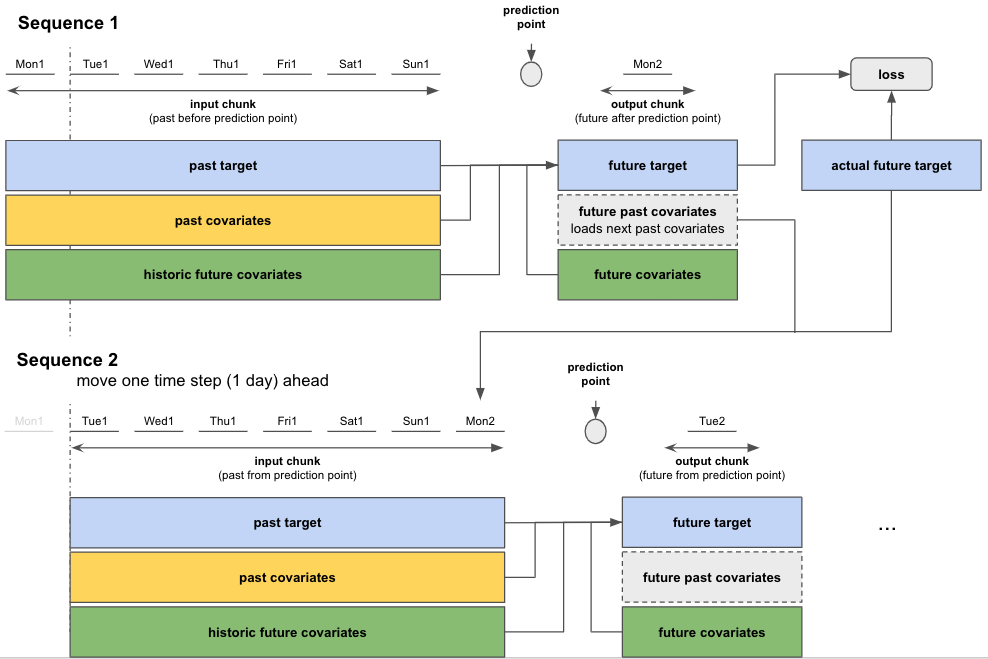
The above diagrams provide a description of the data flow during training and inference. During training, the model feeds past covariates up to input_chunk_length into the training sample, and makes a prediction of output_chunk_length. The input_chunk_length is analogous to the concatenate_features parameter in the other models, which specifies how many past states to concatenate together to form the training sample. The primary difference is that darts handles the concatenation internally, and does not do operations like padding or pooling.
During training, you have to ensure that your input_chunk_length is no bigger than your smallest episode. This is because the model will try to create a training sample of size input_chunk_length, and needs to be able to look that far back into an episode in order to make a prediction.
In our use-case, we will almost always have output_chunk_length set to 1, since we only waIn our use-case, we will almost always have output_chunk_length set to 1, since we only want to predict one time-step ahead (because we will always receive new actions at every iteration). It may be possible that you wan to predict at a lower time-frequency than what you received during training, in which case it may still make sense to have a larger output_chunk_length than 1 and then pick the last predicted value, so we have left this option open to the user.
Users will rarely need to directly interface with the timeseriesclass.py script. Instead, they will use the regular ddm_trainer.py and ddm_predictor.py scripts. To facilitate their use, we have provided example yaml files that are used by both of those scripts. Here is an example for teh n-hits model described earlier:
model:
name: nhits
build_params:
# https://unit8co.github.io/darts/generated_api/darts.models.forecasting.nhits.html
input_chunk_length: 7
output_chunk_length: 1
pl_trainer_kwargs:
accelerator: gpu
gpus: 1
auto_select_gpus: True
fit_params:
epochs: 2
saver:
filename: models/nhits_model
sweep:
run: False
search_algorithm: bayesian
split_strategy: timeseries
num_trials: 3
scoring_func: r2
early_stopping: False
results_csv_path: torch/search_results.csv