Opinions - How to recognize "stuck" instances #1770
-
|
I just wanted to ask and see what everyone's approach is to tracking and recognizing orchestrations and/or entities that get into an unrecoverable "stuck" state. I am starting to design a workflow system having to deal with sale transactions and this area makes me a little uneasy. Thanks! |
Beta Was this translation helpful? Give feedback.
Replies: 8 comments
-
|
(As we discussed on Twitter) I think this comes down to understanding how long your orchestrations typically take to complete. For example, if you have a use case where your orchestrations typically complete between 5 and 10 minutes, then you can query the for running instances that are older then 10 minutes, and begin raising Azure Monitor events/metrics to let you know that something might not be right. However, if the typical orchestration lifetime varies wildly (e.g. you have a human-in-the-loop) then it becomes harder to define what is an acceptable amount of time monitor against. Durable Functions is unsupervised by virtue of its design, so it really is a hard problem to solve at the user-code level. A challenge with DF is that when a control messages or activity message doesn't get consumed, the orchestration halts or gets "stuck". But this isn't a problem that is unique to DF. I get it with Service Bus every now and again on other Azure Functions. Its a systemic problem with queue based systems. Something needs to observe message consumption, or lack of, and raise alerts/auto-heal appropriately. I don't know who is responsible for that something, but I would say it probably should fall on the side of the platform provider, because serverless /PaaS. |
Beta Was this translation helpful? Give feedback.
-
|
anyone else care to share? :) |
Beta Was this translation helpful? Give feedback.
-
|
It depends on what you mean by "stuck" and how much data you are ok with losing ;) I once shipped a change to production that, due to a bug, filled the queues to several thousand each by sending the same signals to the same hundred or so entities in an infinite loop. At least 10 thousand per queue before I noticed. At the rate the app was churning through items, actual work was delayed for several days. So, I just cleared the queues. Who knows what was lost, but it was better than waiting for several days to consume all the items. Any issues arising from that could be dealt with on a case-by-case basis. I suggest putting together some monitoring that looks at queue depth. If it gets above a certain number (depending on your functions) your customers/users will begin experiencing degradation in your service and you might have a fire on your hands. If you can't lose any data, it might be ideal to bump up the number of |
Beta Was this translation helpful? Give feedback.
-
data loss...zero :) @olitomlinson i actually was not even thinking about the case where messages would not get consumed (didn't realize this could happen). I was more so focusing on the orchestration instance status staying "running" when in fact the orchestration completed. |
Beta Was this translation helpful? Give feedback.
-
I don't think that can happen since it would just pick back up where it was running before and complete it again. I may be wrong though, but that's what I "think" would happen. |
Beta Was this translation helpful? Give feedback.
-
No it's definitely happens (happened) if you check the issue log but it could have very well been fixed with the most recent versions. |
Beta Was this translation helpful? Give feedback.
-
|
I suppose it could happen if your orchestration is waiting on an external event and the external event gets lost. I handle this by setting a custom status on the orchestration after receiving an external event, then have a "watchdog" orchestration that makes sure nothing is waiting for external events for too long. Basically the pattern looks like The watchdog is generalized. I just start a watchdog orchestration and pass it the current orchestration's Id, handled in a base class. Then I just call PS. You can also set timeouts on most orchestrations, but I think that the likelihood of two orchestrations getting stuck somewhere is less than one. I have run into issues where the watchdog orchestration is in a different task/control queue than the orchestration and the orchestration's task/control queue gets bogged down. Then the watchdog sees that the orchestration isn't working (it's just behind) and will kill it. So, there's a lot to tune there. It's not perfect. |
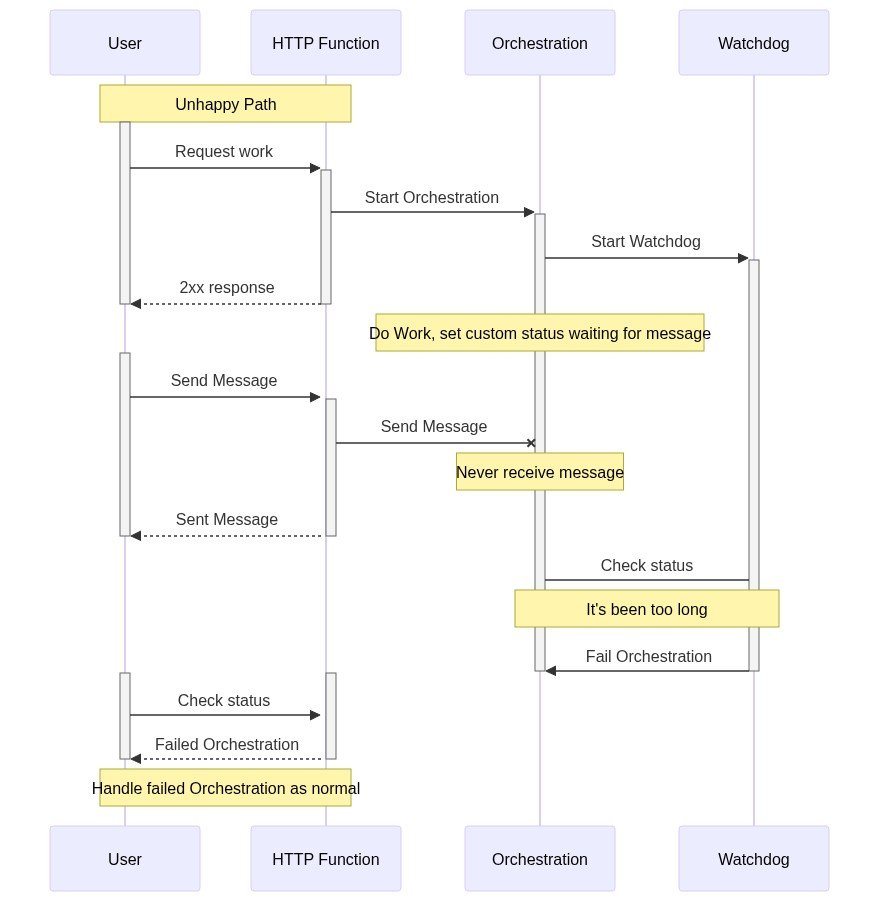
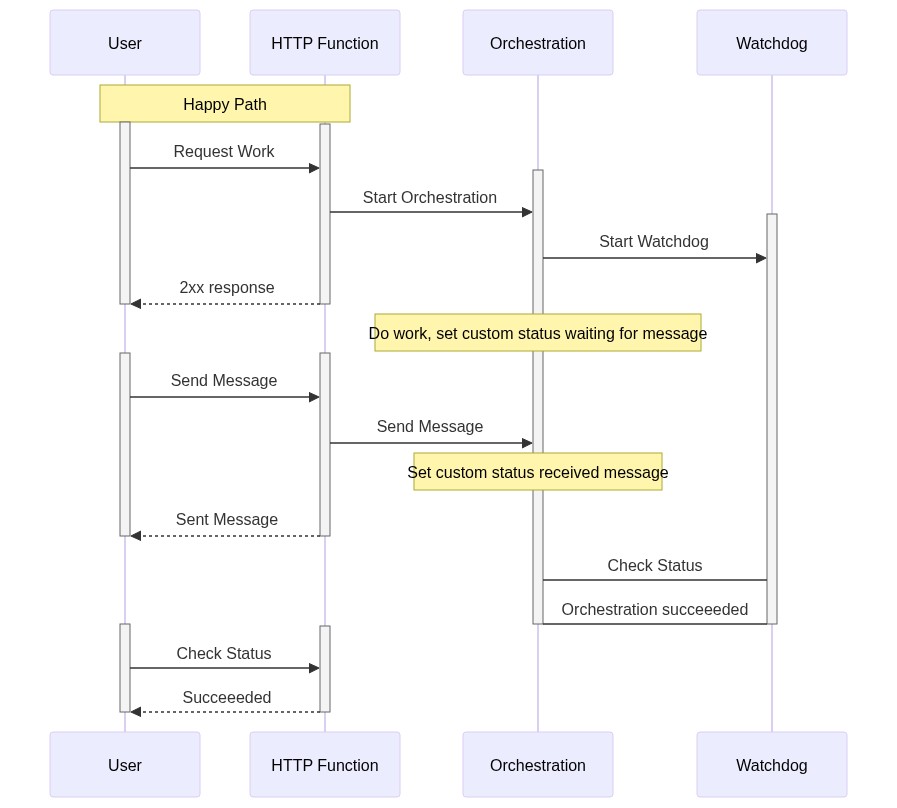
Beta Was this translation helpful? Give feedback.
-
|
If you don't want to use a watchdog process, you can use the overload on
P.s. I recommend doing this anyway as a good practice. It helps weed-out and start a discussion around those "what if" scenarios that often don't get discussed until 6 months down the line when your app enters an illegal state in production at 4am... |
Beta Was this translation helpful? Give feedback.
(As we discussed on Twitter) I think this comes down to understanding how long your orchestrations typically take to complete.
For example, if you have a use case where your orchestrations typically complete between 5 and 10 minutes, then you can query the for running instances that are older then 10 minutes, and begin raising Azure Monitor events/metrics to let you know that something might not be right.
However, if the typical orchestration lifetime varies wildly (e.g. you have a human-in-the-loop) then it becomes harder to define what is an acceptable amount of time monitor against.
Durable Functions is unsupervised by virtue of its design, so it really is a hard problem to solve at th…